OCR算法、模型综述
Last updated on December 9, 2024 pm
1. 引言
1.1 什么是OCR
OCR俗称光学字符识别,英文全称是Optical Charater Recognition(简称OCR),它是利用光学技术和计算机技术把印刷在或者写在图纸上的文字以文本形式提取出来,并转换成一种计算机能够接受、人又可以理解的格式。OCR技术是实现文字快速录入的一项关键技术。在信息社会时代,每天会产生大量的票据、表单、证件数据,这些数据要电子化,需要利用OCR技术进行提取录入。在深度学习没有全面推广之前,大部分OCR识别都是基于传统的方法进行检测识别。在背景单一、数据场景简单的情况下,传统OCR一般都能达到好的效果,但在一些场景复杂、干扰多的情况下,识别效果不好,这个时候深度学习OCR就能体现出巨大的优势。
1.2 传统OCR与深度学习OCR
传统OCR(Optical Character Recognition,光学字符识别)方法是指在深度学习兴起之前广泛使用的一种将图片中的文字转化为计算机可识别文字的技术手段。它主要通过图像处理和统计机器学习方法来达成这一目的。传统OCR技术能够对纸上打印的字符进行识别,支持多场景、任意版型(如英文、字母、数字等)的文字识别,最初只能将图片中的文字转为纯文本,随着技术发展后来也能识别表格以及将一些固定排版的图片(如证件、票据等)转为结构化的数据 。
从技术实现角度看,传统OCR技术涵盖了多个处理阶段,例如文字区域定位、文字矫正、文字分割、文字识别以及后处理等环节。它利用opencv算法库等工具,运用连通区域分析、MSER(Maximally Stable Extremal Regions,最大稳定极值区域)等技术进行文字区域定位,通过旋转、仿射变换进行文字矫正,采用二值化、过滤噪声来分割文字,再利用逻辑回归、SVM(Support Vector Machine,支持向量机)、Adaboost等分类器识别文字,最后结合规则、语言模型(如HMM - Hidden Markov Model,隐马尔可夫模型)等进行后处理,从而提高识别的准确性和有效性
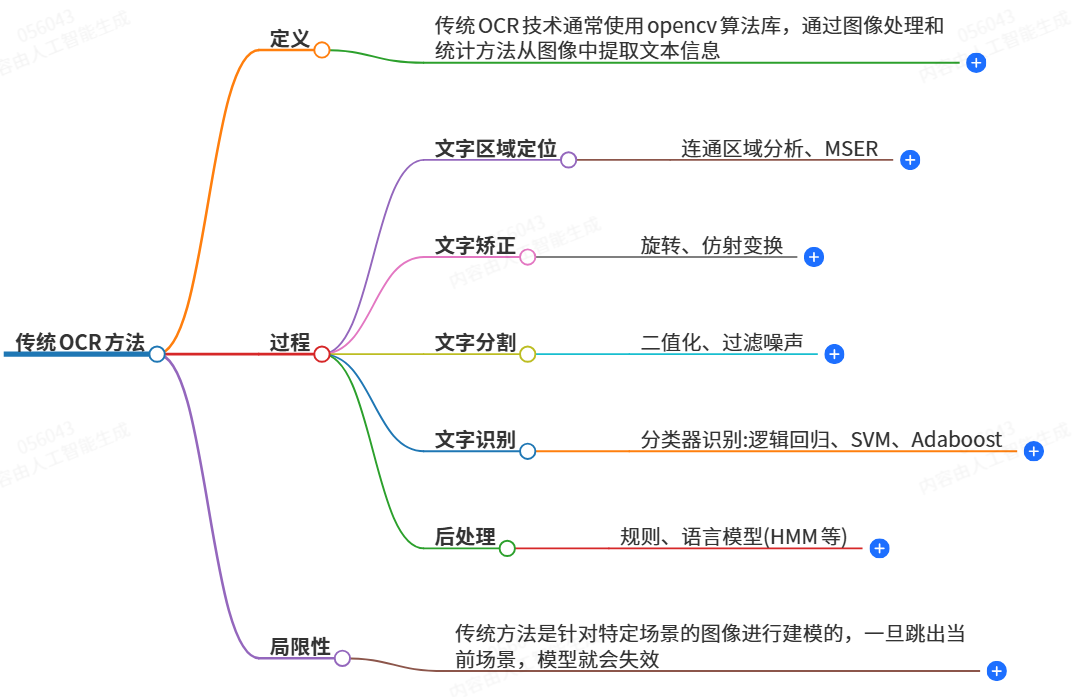
深度学习OCR方法可以分为两阶段算法和端到端的算法。两阶段OCR算法分为文本检测和识别算法,文本检测算法从图像中得到文本行的检测框,然后识别算法识别文本框中的内容。
端对端OCR算法使用一个模型同时完成文字检测和文字识别,因此端对端模型更小,速度更快。
相对于传统OCR方法,深度学习OCR方法准确率较高,速度可能慢一点。
传统OCR方法的优缺点
(一)优点
- 处理简单场景效果好
- 对于简单场景下的图片,传统OCR已经取得了很好的识别效果。例如在一些格式规范、文字清晰、背景简单的文档识别中,传统OCR能够准确地识别出文字内容。像标准格式的发票识别,发票上的文字排版相对固定,字体规范,传统OCR可以有效地提取出发票号码、金额、日期等关键信息。在这种简单场景下,传统OCR的识别准确率可以达到较高水平,满足基本的业务需求,如财务报销中的发票信息录入等 8。
- 运行速度较快
- 传统OCR技术通常比基于深度学习的OCR(aiOCR)更快,因为它不需要进行大量的训练和学习。在处理一些常规的、规则排列的文字时,传统OCR可以迅速地进行识别。例如在识别大量的、格式统一的表格数据时,传统OCR能够快速地对表格中的文字进行定位、分割和识别,不需要像深度学习模型那样进行复杂的神经网络前向传播和反向传播计算。这使得传统OCR在一些对速度要求较高、数据格式相对简单的应用场景中具有优势,如快递单的信息识别,在快递分拣过程中,需要快速地识别出寄件人和收件人的姓名、地址、电话号码等信息,传统OCR可以在较短的时间内完成识别任务 16。
- 成本较低
- 传统OCR技术通常比较便宜,并且可以在低端硬件上运行。它不需要高端的图形处理单元(GPU)等昂贵的硬件设备来支持计算。对于一些预算有限的企业或个人用户来说,传统OCR技术是一种经济实惠的选择。例如,一些小型企业在进行文档数字化时,如果只是处理一些简单的文档类型,采用传统OCR技术可以在较低的成本下实现文字的识别和转换。而且,传统OCR技术在软件授权方面也相对较为便宜,不需要像一些基于深度学习的OCR软件那样支付高额的软件使用费用 16。
(二)缺点
- 对复杂场景适应性差
- 传统OCR方法是针对特定场景的图像进行建模的,一旦跳出当前场景,模型就会失效。例如,在处理自然场景中的文字时,如街景中的招牌、车身广告上的文字等,这些文字可能存在字体多样、大小不一、排列不规则、背景复杂(包含各种图案、光影变化等)的情况,传统OCR技术往往难以准确识别。再如手写文字的识别,由于每个人的书写风格差异很大,传统OCR很难对各种手写字体进行准确识别,其识别准确率会大幅下降 8。
- 识别精度有限
- 对于复杂的文本,如包含多种字体、字号、颜色变化以及特殊排版(如艺术字、斜体字与正体字混合排版等)的文本,传统OCR技术可能会出现错误。在处理一些低质量的图像,如模糊、有污渍或者光照不均匀的图像时,传统OCR的识别准确性也会受到严重影响。例如,在识别一张被水浸湿过的纸质文档上的文字时,由于纸张的变形、文字的模糊等原因,传统OCR可能无法正确识别出所有的文字内容 16。
- 需要专门培训人员
- 传统OCR技术需要专门培训人员进行使用和维护。其参数调整、算法优化等操作需要一定的专业知识和经验。例如,在使用传统OCR软件进行特定文档类型的识别时,可能需要根据文档的特点(如字体类型、排版格式等)对识别算法的参数进行调整,这就要求操作人员具备相关的技术知识,而这种专业人才相对较少,增加了企业或组织使用传统OCR技术的人力成本和难度 16。
- 对格式保留困难
- 传统OCR技术在将纸质文档转换为电子文本时,可能无法完全保留原始文档的格式、排版和图表等信息。例如,在识别一份包含表格和图片的文档时,传统OCR可能只能识别出表格中的文字内容,而无法准确还原表格的结构和样式,对于图片更是无法直接转换为电子文档中的可编辑元素,这在一定程度上影响了文档转换的完整性和可用性。
2. 传统OCR方法
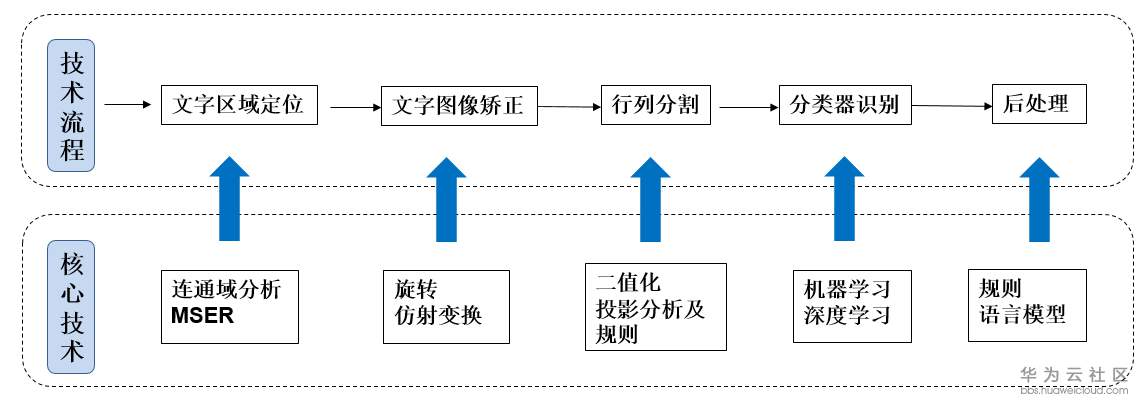
传统OCR方法主要分为文字区域定位、文字图像矫正、行列分割、分类器识别和后处理。按处理方式划分为三个阶段:预处理阶段、识别阶段和后处理阶段。
2.1 文字区域定位
- 传统OCR方法在处理图像时,首先要进行文字区域定位。这一过程常采用连通区域分析和MSER算法。连通区域分析是基于图像中像素的连通性,将具有相似特征(如颜色、灰度值等)的像素划分为不同的区域。例如,在一张包含文字和背景的图像中,文字部分的像素与背景像素在灰度或颜色上可能存在差异,通过连通区域分析可以初步找出可能是文字的区域。
- MSER算法则是通过寻找图像中的极值区域,这些区域在一定的阈值变化范围内是最稳定的。对于文字来说,其字符形状相对稳定,在不同的灰度阈值下,字符所在区域往往表现出极大值或极小值的特性。通过这种方式,可以更精确地定位文字所在的区域
2.2 文字图像矫正
- 当图像中的文字存在倾斜或扭曲时,就需要进行文字矫正。这一阶段通常使用旋转和仿射变换。旋转是针对文字整体存在一定角度倾斜的情况,通过计算倾斜角度,将文字区域旋转到水平或垂直方向。例如,在扫描纸质文档时,如果文档放置稍有倾斜,扫描得到的图像中的文字也会倾斜,此时就可以根据文字的边界或者特定的算法来确定倾斜角度并进行旋转操作。
- 仿射变换则更通用,它可以处理文字的拉伸、压缩以及更复杂的变形情况。它通过对图像中的坐标进行线性变换,将变形后的文字映射回正常的形状,从而为后续的文字分割和识别提供更有利的条件。
2.3 行列分割
- 在文字分割阶段,传统OCR采用二值化和过滤噪声等操作。二值化是将图像的像素值转换为只有0和1的二值形式,这样可以突出文字与背景的对比。例如,将文字部分设为1(白色),背景设为0(黑色)或者反之。通过这种方式,可以简化图像的复杂度,使得文字的轮廓更加清晰。
- 过滤噪声则是去除图像中的干扰因素,如扫描过程中产生的小斑点、划痕等。这些噪声可能会被误识别为文字的一部分,通过滤波算法(如中值滤波、高斯滤波等)可以去除这些不必要的干扰,提高文字分割的准确性。
2.4 分类器识别
分类器识别过程是在提取了字符图像之后,对其进行分析和分类,以确定每个字符对应的符号或文字。以下是这一过程的详细说明:
特征提取
在进行分类之前,OCR系统首先需要从图像中提取出字符的特征。这可能包括:
- 几何特征:如字符的高度、宽度、笔画数量等。
- 统计特征:例如像素分布、边缘检测结果等。
- 拓扑结构:字符内部的连通性或断开情况。
- 频域特征:通过傅里叶变换或其他频域分析方法获得的特征。
这些特征能够描述字符的独特属性,有助于后续的分类工作。
分类器训练
为了实现准确的分类,OCR系统通常会使用机器学习算法来构建分类器。训练阶段涉及以下几个方面:
- 数据准备:收集大量带有标签的字符图像作为训练样本。每个样本都包含一个字符图像及其对应的正确标签(即该字符的真实值)。
- 选择模型:根据任务需求选择合适的分类算法,如支持向量机(SVM)、K近邻(KNN)、神经网络等。
- 训练过程:利用训练集中的数据对选定的模型进行训练,调整模型参数,使得模型能够学习到如何基于输入的特征预测正确的字符标签。
分类与决策
一旦分类器被训练好,就可以用于实际的字符识别:
- 输入处理:当一个新的字符图像输入时,系统首先会提取其特征。
- 分类预测:然后使用训练好的分类器对这些特征进行评估,输出最有可能的字符标签。
- 后处理:有时还会有一个后处理步骤,比如语言模型的应用,来修正识别结果中的拼写错误或者不符合语法的地方,提高整体准确性。
分类器识别是传统OCR方法的核心部分,它决定了系统能否准确地将图像中的字符转换成文本。通过精心设计的特征提取、有效的分类算法和充足的训练数据,可以显著提高OCR系统的准确性和鲁棒性。
2.5 后处理
- 传统OCR的后处理阶段会利用规则和语言模型来提高识别的准确性。规则可以是基于语法、格式等方面的规定。例如,在识别身份证号码时,根据身份证号码的固定格式(18位数字,特定的编码规则等),对识别结果进行校验和修正。
- 语言模型如HMM也会被应用。HMM是一种统计模型,它基于马尔可夫链假设,对文字的序列进行建模。在文字识别中,它可以根据语言的概率分布来纠正识别结果中的错误。例如,在识别一段英文句子时,如果某个单词被识别为不符合语法规则的形式,HMM可以根据语言的统计规律,推荐最可能的正确单词。
3. 深度学习OCR方法
3.1 两阶段OCR
| 文本检测算法模型 | 文字识别算法模型 | |
|---|---|---|
| CTPN | CRNN | |
| SegLink | RARE | |
| EAST | RAN | |
| PSENet | ASTER | |
| DBNet | MORAN | |
| FCENet | SRN | |
| Texboxes | STAR-Net | |
| CRAFT | Rosetta | |
| LOMO | SAR | |
| SPCNet | R2AM | |
| PAN | ||
| DB |
3.2 端到端OCR
与两阶段OCR不同,端到端OCR不需要先进行文字检测然后再进行文字识别这样明确的分阶段操作。它直接在整个图像上进行操作,将图像中的文字信息直接转换为文本。这样做的好处是避免了由于分阶段处理带来的误差累积问题。例如,在两阶段OCR中,如果文字检测阶段出现错误,那么在识别阶段就会基于错误的检测结果进行操作,而端到端OCR则不存在这种情况,因为它是从图像到文本的直接映射。并且,将检测和识别统一到一个模型里面,就使得图像的feature可以被共享利用。
| OCR算法模型 | Title |
|---|---|
| Towards End-to-end Text Spotting with Convolution Recurrent Neural Network | |
| FOTS | FOTS: Fast Oriented Text Spotting with a Unified Network |
| Mask TextSpotter | Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes |
| CharNet | Convolutional Character Networks |
| Mask TextSpotterV3 | Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Text Spotting |
| PGNet | [2104.05458] PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network |
| ABCNet | |
| TrOCR | TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models |
| SVTRv2 | SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition |
| GOT-OCR | Ucas-HaoranWei/GOT-OCR2.0: Official code implementation of General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model |
3.3 多模态OCR

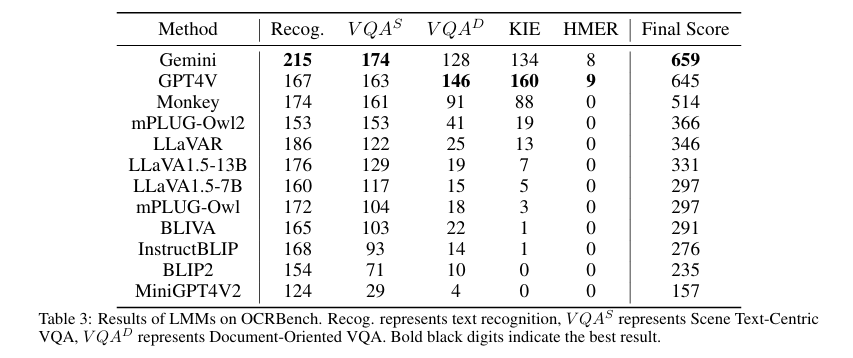
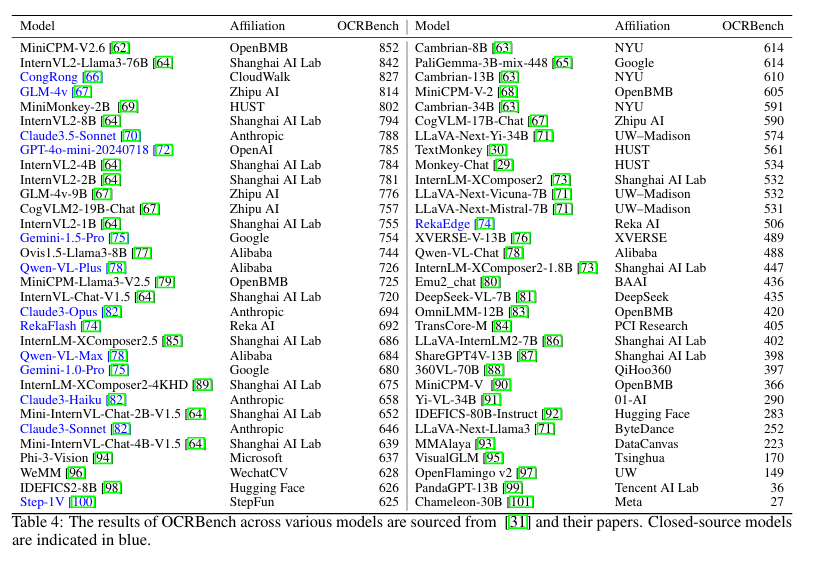
4. OCR应用方向
4.1 文字识别
普通文字识别
场景文字识别
数学公式识别
从图片中提取数学公式,转换为markdown或者Latex
4.2 文档结构化识别(版面分析)
页眉
页脚
数学公式
图表的Caption
图片
表格
段落文本
段落标题
列表
4.3 关键信息抽取
关键信息提取(Key Information Extraction,KIE)是Document VQA中的一个重要任务,主要从图像中提取所需要的关键信息,如从身份证中提取出姓名和公民身份号码信息,这类信息的种类往往在特定任务下是固定的,但是在不同任务间是不同的。
KIE通常分为两个子任务进行研究:
- SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
- RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。
一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)[4]来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的原理可以将这些方法分为下面四种:
- 基于Grid的方法
- 基于Token的方法
- 基于GCN的方法
- 基于End to End 的方法
5. OCR相关工具
PaddleOCR:通用OCR工具
Tesseract: 普通文字识别
Umi-OCR: 普通文字识别、文档解析
MinerU:将PDF转换成Markdown和JSON格式
LaTeX-OCR: 数学公式识别
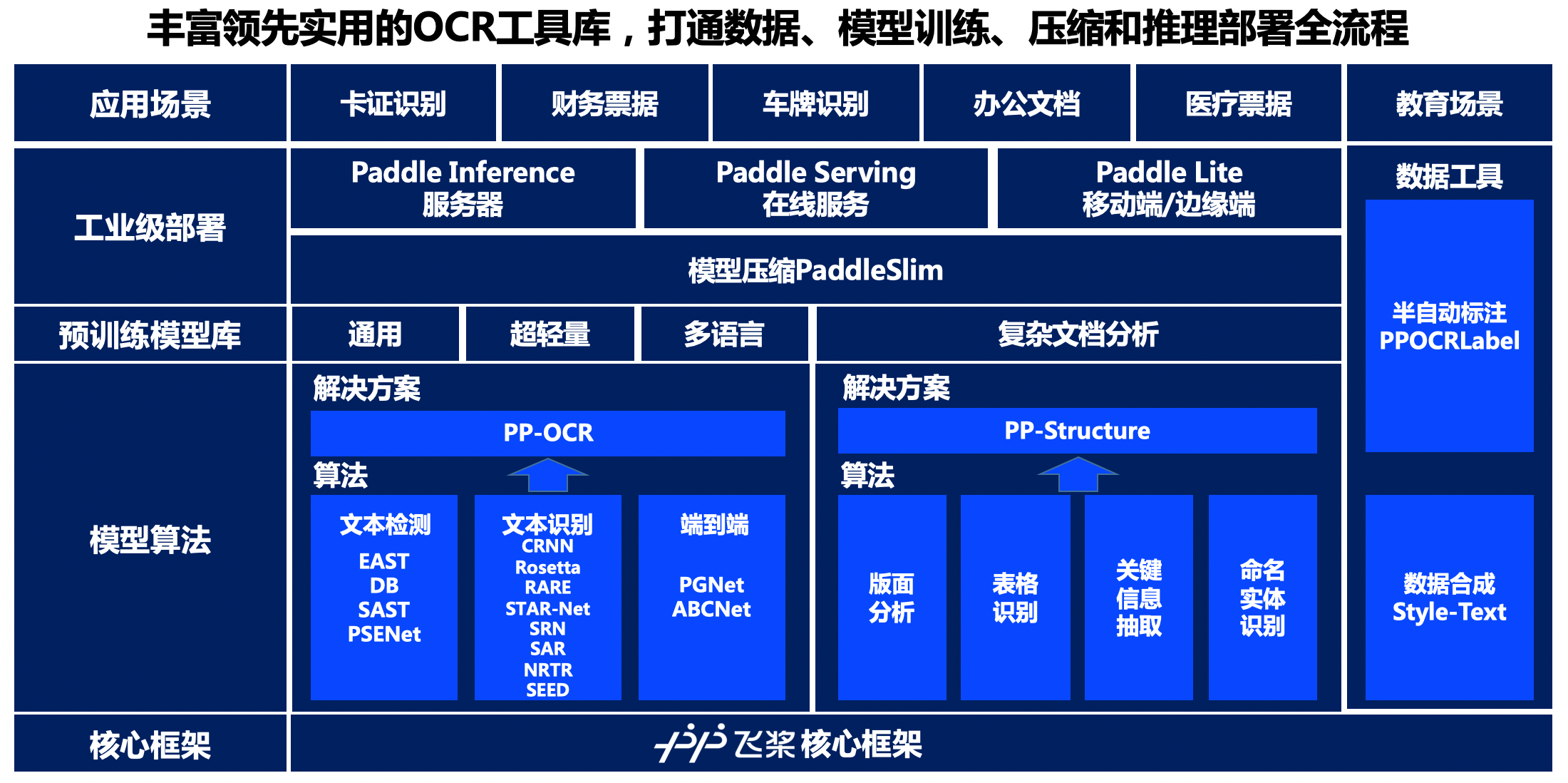
Dive-into-OCR/notebook_ch/1.introduction/OCR技术导论.ipynb at main · PaddleOCR-Community/Dive-into-OCR
【多模态】29、OCRBench | 为大型多模态模型提供一个 OCR 任务测评基准-CSDN博客
文章合集:https://github.com/chongzicbo/ReadWriteThink
