YOLO模型的全面综述
Last updated on December 9, 2024 pm
摘要
本研究对YOLO (You Only Look Once) 的各个版本进行了全面的基准测试分析,从 YOLOv3 到最新的算法。它代表了首次全面评估 YOLO11 性能的研究,YOLO11 是 YOLO 系列的最新成员。它评估了它们在三个不同数据集上的性能:交通标志(具有不同的对象大小)、非洲野生动物(具有不同的纵横比,每个图像至少有一个对象实例)以及船舶和船只(具有单个类别的小型对象),确保在具有不同挑战的数据集之间进行全面评估。为了确保稳健的评估,我们采用了一套全面的指标,包括精度、召回率、平均精度均值 (mAP)、处理时间、GFLOP 计数和模型大小。我们的分析强调了每个 YOLO 版本的独特优势和局限性。例如:YOLOv9 表现出很高的准确性,但在检测小物体和效率方面表现不佳,而 YOLOv10 表现出相对较低的准确性,因为架构选择会影响其在重叠物体检测方面的性能,但在速度和效率方面表现出色。此外,YOLO11 系列在准确性、速度、计算效率和模型大小方面始终表现出卓越的性能。YOLO11m 在准确性和效率之间取得了显著的平衡,在交通标志、非洲野生动物和船舶数据集上的mAP50-95得分分别为0.795、0.81和0.325,同时保持了2.4毫秒的平均推理时间,模型大小为38.8Mb,平均约为67.6 GFLOPs。这些结果为工业界和学术界提供了重要的见解,有助于为各种应用选择最合适的 YOLO 算法,并指导未来的增强功能。
引言
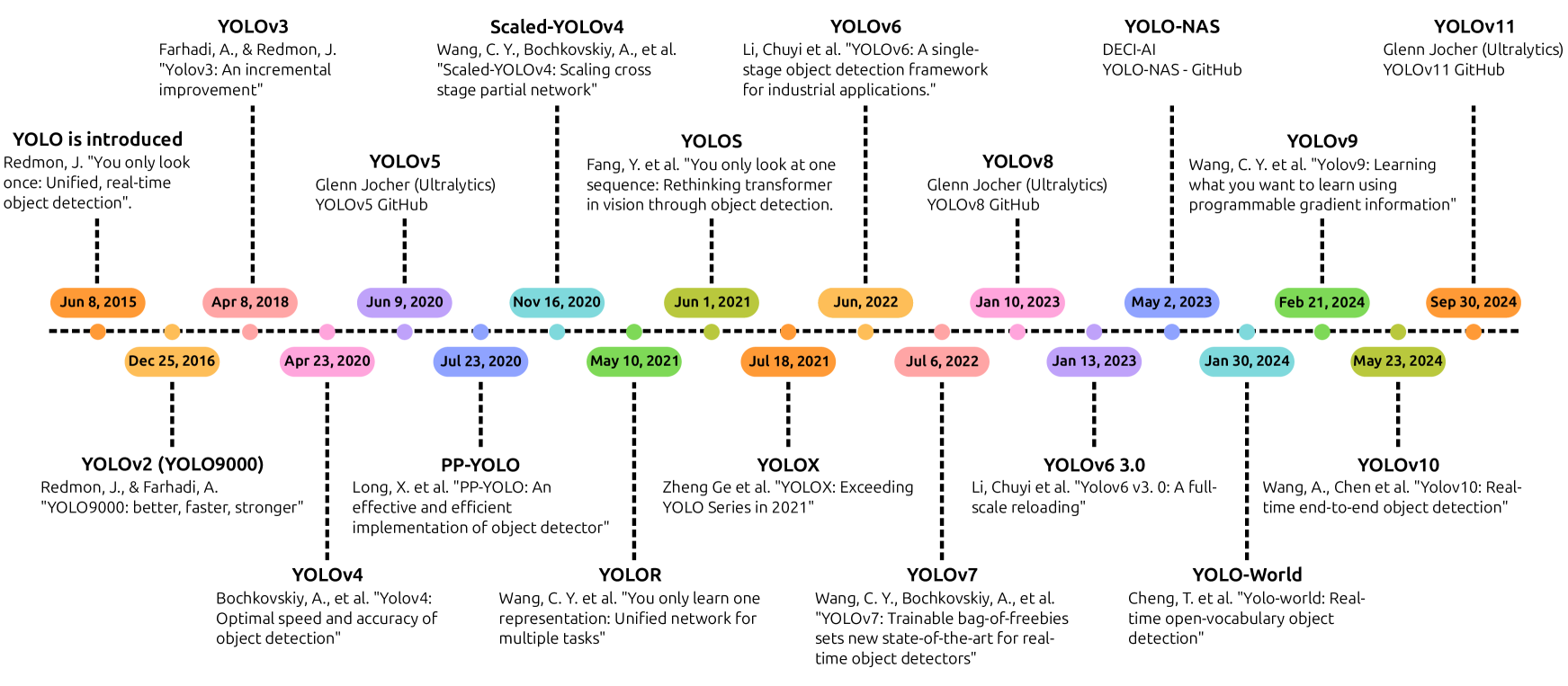
Figure 1:Evolution of YOLO Algorithms throughout the years.
主要介绍了物体检测在计算机视觉系统中的重要性及其应用,并概述了YOLO(You Only Look Once)算法的发展历程和优势。
- 物体检测的重要性:物体检测是计算机视觉系统的关键组成部分,广泛应用于自动驾驶、机器人技术、库存管理、视频监控和体育分析等领域。
- 传统方法的局限性:传统的物体检测方法如Viola-Jones算法和DPM模型在鲁棒性和泛化能力上存在局限,而深度学习方法已成为主流。
- 一阶段与两阶段方法:一阶段方法如RetinaNet和SSD在速度和准确性之间取得平衡,而两阶段方法如R-CNN提供高精度但计算密集。
- YOLO算法的崛起:YOLO算法以其鲁棒性和效率脱颖而出,自2015年首次提出以来,通过不断改进框架和设计,成为实时物体检测的领先算法。
- YOLO算法的演进:YOLO算法的演进包括从YOLOv1到YOLOv11的多个版本,每个版本都引入了新的架构和技术来提高性能。
- Ultralytics的角色:Ultralytics在YOLO算法的发展中扮演了重要角色,通过维护和改进模型,使其更易于访问和定制。
- 研究目的:本研究旨在对YOLO算法的演变进行全面比较分析,特别是对最新成员YOLO11进行首次全面评估,并探讨其在不同应用场景中的优势和局限性。
- 研究方法:研究使用了三个多样化的数据集,并采用了一致的超参数设置,以确保公平和无偏见的比较。
- 研究贡献:研究的贡献在于提供了对YOLO11及其前身的全面比较,深入分析了这些算法的结构演变,并扩展了性能评估指标,为选择最适合特定用例的YOLO算法提供了宝贵的见解。
相关工作
主要回顾了YOLO算法的演变、不同版本的架构、以及与其他计算机视觉算法的基准测试。以下是对该章节的详细总结分析:
YOLO算法的演变:
- 论文[14]分析了包括YOLOv8在内的七种语义分割和检测算法,用于云层分割的遥感图像。
- 论文[22]回顾了YOLO从版本1到版本8的演变,但没有考虑YOLOv9、YOLOv10和YOLO11。
- 论文[12]详细分析了从YOLOv1到YOLOv4的单阶段物体检测器,并比较了两阶段和单阶段物体检测器。
- 论文[53]探讨了YOLO从版本1到10的演变,强调了其在汽车安全、医疗保健等领域的应用。
- 论文[61]讨论了YOLO算法的发展直到第四版,并提出了新的方法和挑战。
- 论文[27]分析了YOLO算法的发展和性能,比较了从第8版到第8版的YOLO版本。
YOLO算法的应用:
- YOLO算法在自动驾驶、医疗保健、工业制造、监控和农业等领域有广泛应用。
- YOLOv8提供了多种应用,包括实例分割、姿态估计和定向物体检测(OOB)。
YOLO算法的基准测试:
- 论文[14]进行了云层分割的基准测试,评估了不同算法的架构方法和性能。
- 论文[22]提出了结合联邦学习以提高隐私、适应性和协作训练的通用性。
- 论文[12]提供了单阶段和两阶段物体检测器的比较。
- 论文[53]探讨了YOLO算法对未来AI驱动应用的潜在整合。
- 论文[61]强调了YOLO算法在物体检测方面的挑战和需要进一步研究的地方。
YOLO算法的挑战:
- YOLO算法在处理小物体和不同旋转角度的物体时面临挑战。
- YOLOv9、YOLOv10和YOLO11的最新模型在准确性和效率方面表现出色,但在某些情况下仍需改进。
YOLO算法的改进:
- YOLOv9引入了信息瓶颈原理和可逆函数来保留数据,提高了模型的收敛性和性能。
- YOLOv10通过增强的CSP-Net主干和PAN层提高了梯度流动和减少了计算冗余。
- YOLO11引入了C2PSA模块,结合了跨阶段部分网络和自注意力机制,提高了检测精度。
YOLO算法的未来方向:
- 未来的研究可以专注于优化YOLOv10以提高其准确性,同时保持其速度和效率优势。
- 继续改进架构设计可能会带来更先进的YOLO算法。
研究贡献:
- 本研究首次全面比较了YOLO11及其前身,并在三个多样化的数据集上评估了它们的性能。
- 研究结果为工业界和学术界提供了选择最适合特定应用场景的YOLO算法的宝贵见解。
通过这些分析,可以看出YOLO算法在不断演进和改进,以适应不同的应用需求和挑战。
Benchmark 设置
数据集
介绍了三种数据集,分别是Traffic Signs Dataset、Africa Wildlife Dataset和Ships/Vessels Dataset。以下是对这三种数据集的详细介绍:
1. Traffic Signs Dataset(交通标志数据集)
- 来源:由Radu Oprea在Kaggle上提供的开源数据集。
- 特点:
- 包含约55个类别的交通标志图像。
- 训练集包含3253张图像,验证集包含1128张图像。
- 图像大小不一,初始尺寸为640x640像素。
- 为了平衡不同类别的数量,采用了欠采样技术。
- 应用领域:自动驾驶、交通管理、道路安全和智能交通系统。
- 挑战:
- 目标物体大小变化较大。
- 不同类别之间的模式相似,增加了检测难度。
2. Africa Wildlife Dataset(非洲野生动物数据集)
- 来源:由Bianca Ferreira在Kaggle上设计的开源数据集。
- 特点:
- 包含四种常见的非洲动物类别:水牛、大象、犀牛和斑马。
- 每个类别至少有376张图像,通过Google图像搜索收集并手动标注为YOLO格式。
- 数据集分为训练集、验证集和测试集,比例为70%、20%和10%。
- 应用领域:野生动物保护、反偷猎、生物多样性监测和生态研究。
- 挑战:
- 目标物体的宽高比变化较大。
- 每张图像至少包含一种指定的动物类别,可能还包含其他类别的多个实例或发生情况。
- 目标物体重叠,增加了检测难度。
3. Ships/Vessels Dataset(船舶数据集)
- 来源:由Siddharth Sah从多个Roboflow数据集中收集并整理的开源数据集。
- 特点:
- 包含约13.5k张图像,专门用于船舶检测。
- 每张图像都使用YOLO格式手动标注了边界框。
- 数据集分为训练集、验证集和测试集,比例为70%、20%和10%。
- 应用领域:海事安全、渔业管理、海洋污染监测、国防、海事安全和更多实际应用。
- 挑战:
- 目标物体(船舶)相对较小。
- 目标物体具有不同的旋转角度,增加了检测难度。
这些数据集在对象检测研究中具有重要意义,因为它们涵盖了不同大小、形状和密度的对象,能够全面评估YOLO算法在不同场景下的性能。
模型
比较分析:Ultralytics vs 原始YOLO模型
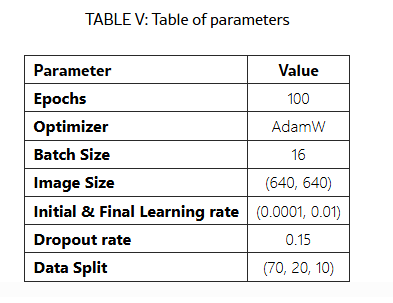
在Traffic Signs数据集上,对Ultralytics提供的版本和原始模型进行比较分析,使用相同的超参数设置如表V所示。目标是为了强调突出Ultralytics提供的版本和原始模型之间的差异。由于Ultraytics缺乏对YOLO v4、YOLO v6、YOLO v7的支持,因此本文将这几个YOLO版本排除在外了。
Ultralytics支持库中的模型和任务
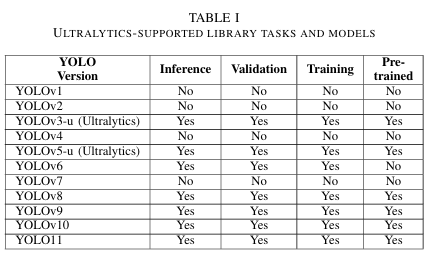
根据表I,Ultralytics库为研究人员和程序员提供了各种YOLO模型,用于推理、验证、训练和导出。我们注意到Ultralytics不支持YOLOv1、YOLOv2、YOLOv4和YOLOv7。对于YOLOv6,库只支持配置文件.yaml,而不支持预训练的.pt模型。
Ultralytics和原始模型的性能比较
通过对Ultralytics模型及其原始版本在交通标志数据集上的比较分析,我们观察到Ultralytics版本和原始版本之间存在显著差异。例如,Ultralytics版本的YOLOv5n(nano)和YOLOv3表现优越,突显了Ultralytics所做的增强和优化。相反,原始版本的YOLOv9c(compact)略微优于其Ultralytics版本,可能是由于Ultralytics对该较新模型的优化不足。这些观察结果表明,Ultralytics模型经过了大量修改,直接比较原始版本和Ultralytics版本是不公平和不准确的。因此,本文将专注于Ultralytics支持的版本,以确保基准测试的一致性和公平性。
YOLOv3u

YOLOv3基于其前身,旨在提高定位错误和检测效率,特别是对于较小的物体。它使用Darknet-53框架,该框架有53个卷积层,速度是ResNet-152的两倍。YOLOv3还结合了特征金字塔网络(FPN)的元素,如残差块、跳跃连接和上采样,以增强跨不同尺度的物体检测能力。该算法生成三个不同尺度的特征图,以32、16和8的因子对输入进行下采样,并使用三尺度检测机制来检测大、中、小尺寸物体,分别使用不同的特征图。尽管有所改进,YOLOv3在检测中等和大型物体时仍面临挑战,因此Ultralytics发布了YOLOv3u。YOLOv3u是YOLOv3的改进版本,使用无锚点检测方法,并提高了YOLOv3的准确性和速度,特别是对于中等和大型物体。
YOLOv5u
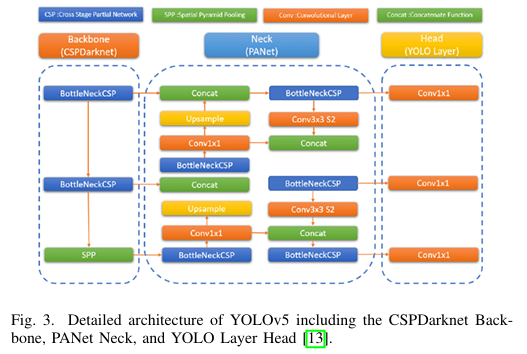
YOLOv5由Glenn Jocher提出,从Darknet框架过渡到PyTorch,保留了YOLOv4的许多改进,并使用CSPDarknet作为其骨干。CSPDarknet是原始Darknet架构的修改版本,通过将特征图分成单独的路径来实现更高效的特征提取和减少计算成本。YOLOv5采用步幅卷积层,旨在减少内存和计算成本。此外,该版本采用空间金字塔池化快速(SPPF)模块,通过在不同尺度上池化特征并提供多尺度表示来工作。YOLOv5实现了多种增强,如马赛克、复制粘贴、随机仿射、MixUp、HSV增强和随机水平翻转。Ultralytics通过YOLOv5u积极改进该模型,采用无锚点检测方法,并在复杂物体的不同尺寸上实现了更好的整体性能。
YOLOv8
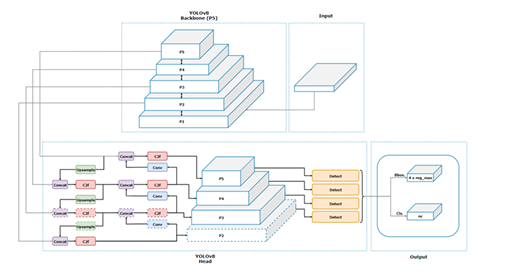
Ultralytics引入了YOLOv8,这是YOLO系列的重大进化,包括五个缩放版本。除了物体检测外,YOLOv8还提供了图像分类、姿态估计、实例分割和定向物体检测(OOB)等多种应用。关键特性包括类似于YOLOv5的主干,调整后的CSPLayer(现称为C2f模块),结合了高级特征和上下文信息以提高检测精度。YOLOv8还引入了一个语义分割模型YOLOv8-Seg,结合了CSPDarknet53特征提取器和C2F模块,在物体检测和语义分割基准测试中取得了最先进的结果,同时保持了高效率。
YOLOv9
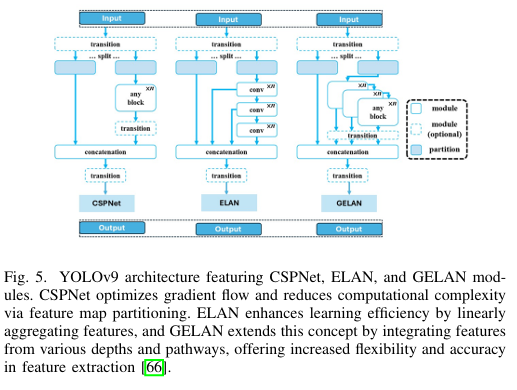
YOLOv9由Chien-Yao Wang、I-Hau Yeh和Hong-Yuan Mark Liao开发,使用信息瓶颈原理和可逆函数来在网络深度中保留关键数据,确保可靠的梯度生成并提高模型收敛性和性能。可逆函数可以在不丢失信息的情况下反转,这是YOLOv9架构的另一个基石。这种属性允许网络保持完整的信息流,使模型参数的更新更加准确。此外,YOLOv9提供了五个缩放版本,重点是轻量级模型,这些模型通常欠参数化,并且在前向过程中容易丢失重要信息。可编程梯度信息(PGI)是YOLOv9引入的一项重大进步。PGI是一种在训练期间动态调整梯度信息的方法,通过选择性关注最具信息量的梯度来优化学习效率。通过这种方式,PGI有助于保留可能在轻量级模型中丢失的关键信息。此外,YOLOv9还包括GELAN(梯度增强轻量级架构网络),这是一种新的架构改进,旨在通过优化网络内的计算路径来提高参数利用和计算效率。
YOLOv10
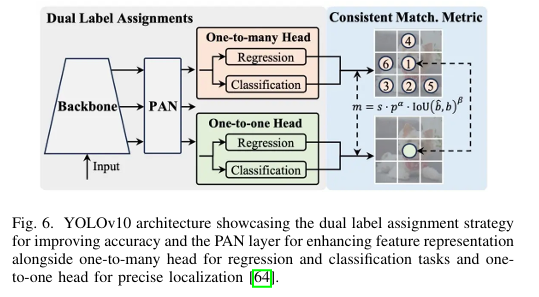
YOLOv10由清华大学的研究人员开发,基于先前模型的优势进行了关键创新。该架构具有增强的CSP-Net(跨阶段部分网络)主干,以提高梯度流动和减少计算冗余。网络结构分为三部分:主干、颈部和检测头。颈部包括PAN(路径聚合网络)层,用于有效的多尺度特征融合。PAN旨在通过聚合不同层的特征来增强信息流,使网络能够更好地捕捉和结合不同尺度的细节,这对于检测不同大小的物体至关重要。此外,该版本还提供五个缩放版本,从纳米到超大。对于推理,One-to-One Head为每个物体生成单个最佳预测,消除了对非极大值抑制(NMS)的需求。通过移除对NMS的需求,YOLOv10减少了延迟并提高了后处理速度。此外,YOLOv10还包括NMS-Free Training,使用一致的双重分配来减少推理延迟,并优化了从效率和准确性角度的各种组件,包括轻量级分类头、空间-通道解耦下采样和排名引导块设计。此外,该模型还包括大核卷积和部分自注意力模块,以在不显著增加计算成本的情况下提高性能。
YOLO11
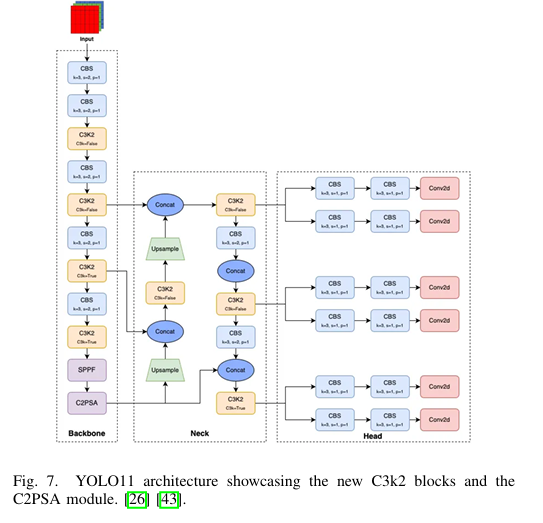
YOLO11是Ultralytics推出的最新创新,基于其前身的发展,特别是YOLOv8。这一迭代提供了从纳米到超大的五种缩放模型,适用于各种应用。与YOLOv8一样,YOLO11包括物体检测、实例分割、图像分类、姿态估计和定向物体检测(OBB)等多种应用。关键改进包括引入C2PSA(跨阶段部分自注意力)模块,结合了跨阶段部分网络和自注意力机制的优势。这使得模型能够在多个层次上更有效地捕获上下文信息,提高物体检测精度,特别是对于小型和重叠物体。此外,在YOLO11中,C2f块被C3k2块取代,C3k2是CSP Bottleneck的自定义实现,使用两个卷积而不是YOLOv8中使用的一个大卷积。这个块使用较小的内核,在保持精度的同时提高了效率和速度。
硬件和软件设置
- 表III:实验的软件设置
- 表IV:6个YOLO版本的不同尺寸的模型

总结了用于评估YOLO模型的硬件和软件环境设置。
- 软件环境:实验使用了Python 3.12、Ubuntu 22.04、CUDA 12.5、cuDNN 8.9.7、Ultralytics 8.2.55和WandB 0.17.4等软件包。
- 硬件环境:实验在两块NVIDIA RTX 4090 GPU上进行,每块GPU拥有16,384个CUDA核心。
- 数据集处理:针对交通标志数据集,应用了欠采样技术以确保数据集平衡,并将图像数量从4381减少到3233张。
- 训练验证测试分割:非洲野生动物数据集和船只数据集分别按照70%训练、20%验证和10%测试的比例进行分割。
- 模型训练:实验中训练了23个模型,涵盖了5种不同的YOLO版本,并使用了相似的超参数以确保公平比较。
- 模型规模:交通标志数据集包含24个类别,平均每个类别约100张图像;非洲野生动物数据集包含4个类别,每个类别至少有376张图像;船只数据集专注于单一类别的小型物体检测。
评估指标
评估指标包括准确性、计算效率和模型大小三个方面:
准确性指标
Precision(精确率):
- 定义:正确预测的观察值与总预测观察值的比率。
- 计算公式:$$ \text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} $$
- 其中,TP(True Positives)为真正例,FP(False Positives)为假正例。
Recall(召回率):
- 定义:正确预测的观察值与所有实际观察值的比率。
- 计算公式:$$ \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}} $$
- 其中,FN(False Negatives)为假反例。
mAP50(Mean Average Precision at an IoU threshold of 0.50):
- 定义:在IoU(Intersection over Union)阈值为0.50时的平均精度均值。
- 计算公式:$$ \text{mAP50} = \frac{1}{|C|} \sum_{c \in C} \text{AP}_c $$
- 其中,$C$ 是类别集合,$\text{AP}_c$ 是类别 $c$ 的平均精度。
mAP50-95(Mean Average Precision across IoU thresholds from 0.50 to 0.95):
- 定义:在IoU阈值从0.50到0.95范围内的平均精度均值。
- 计算公式:$$ \text{mAP50-95} = \frac{1}{15} \sum_{r=1}^{15} \text{AP}_{0.50 + \frac{r-1}{14} \times 0.05} $$
- 其中,$r$ 表示IoU阈值的范围。
计算效率指标
Preprocessing Time(预处理时间):
- 定义:准备原始数据以输入模型所需的持续时间。
Inference Time(推理时间):
- 定义:模型处理输入数据并生成预测所需的持续时间。
Postprocessing Time(后处理时间):
- 定义:将模型的原始预测转换为最终可用格式所需的时间。
Total Time(总时间):
- 定义:预处理时间、推理时间和后处理时间的总和。
GFLOPs(Giga Floating-Point Operations Per Second):
- 定义:模型训练的计算能力,反映其效率。
模型大小指标
- Size(大小):
- 定义:模型的实际磁盘大小及其参数数量。
这些指标提供了对YOLO模型性能的全面概述,有助于在不同真实世界场景中选择最优的YOLO算法。
实验结果和讨论
实验结果
交通信号数据集
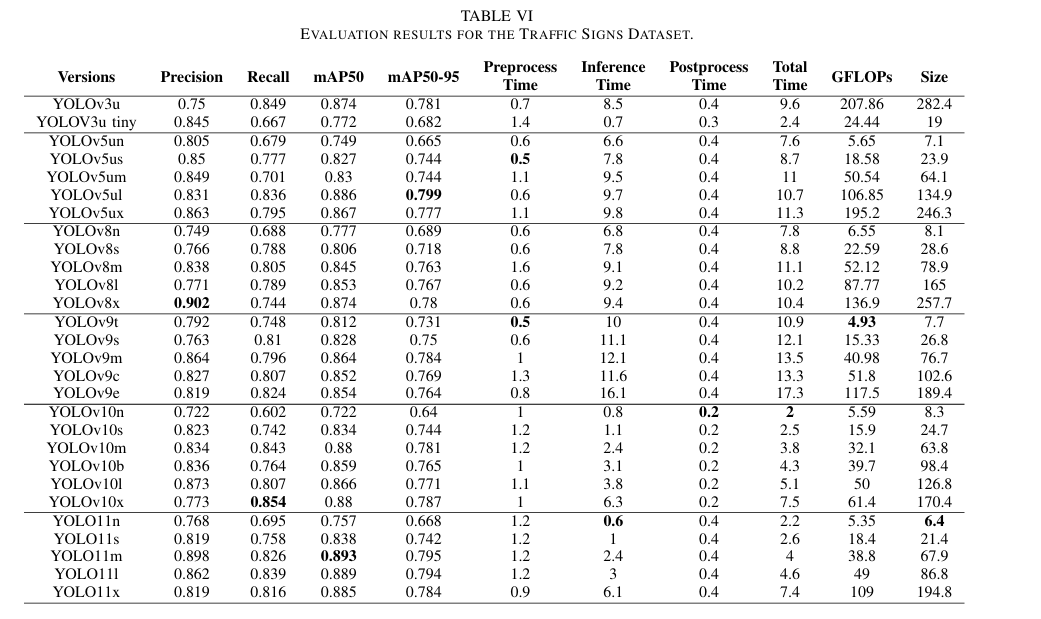
YOLO模型在检测交通标志方面的有效性,展示了各种精度范围。最高的mAP50-95为0.799,而最低的精度为0.64。另一方面,最高的mAP50为0.893,而最低的为0.722。mAP50和mAP50-95之间的显著差距表明,模型在处理不同大小的交通标志时,在较高阈值下遇到了困难,这反映了其检测算法中潜在的改进领域。
a) 准确性:如图8所示,YOLOv5ul展示了最高的准确性,实现了mAP50为0.866和mAP50-95为0.799。紧随其后的是YOLO11m,其mAP50-95为0.795,YOLO11l的mAP50-95为0.794。相比之下,YOLOv10n展示了最低的精度,其mAP50为0.722,mAP50-95为0.64,紧随其后的是YOLOv5un,其mAP50-95为0.665,如数据点在图8中所证明的。
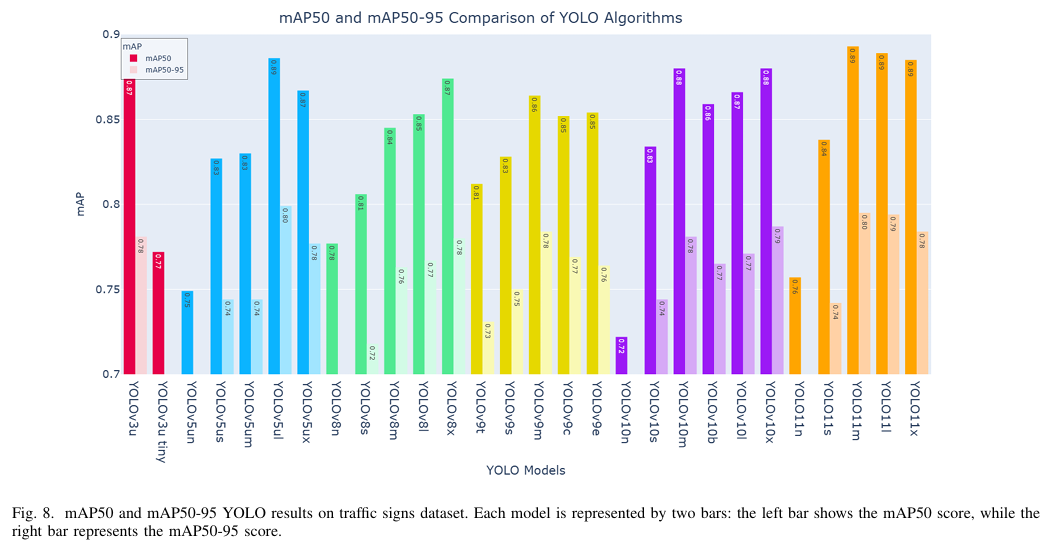
b) 精度和召回率:图9阐明了考虑模型大小的情况下精度和召回率之间的权衡。像YOLO11m、YOLO10l、YOLOv9m、YOLOv5ux和YOLO111这样的模型展示了高精度和召回率,特别是YOLO11m实现了0.898的精度和0.826的召回率,同时模型大小为67.9Mb,而YOLOv10l实现了0.873的精度和0.807的召回率,但模型大小显著更大(126.8 Mb)。相比之下,较小的模型如YOLOv10n(精度0.722,召回率0.602)、YOLOv8n(精度0.749,召回率0.688)和YOLO11n(精度0.768,召回率0.695)在两个指标上都表现不佳。这突显了较大模型在交通标志数据集上的优越性能。此外,YOLOv5um的高精度(0.849)和低召回率(0.701)表明了对假阴性的倾向,而YOLOv3u的高召回率(0.849)和低精度(0.75)则表明了对假阳性的倾向。
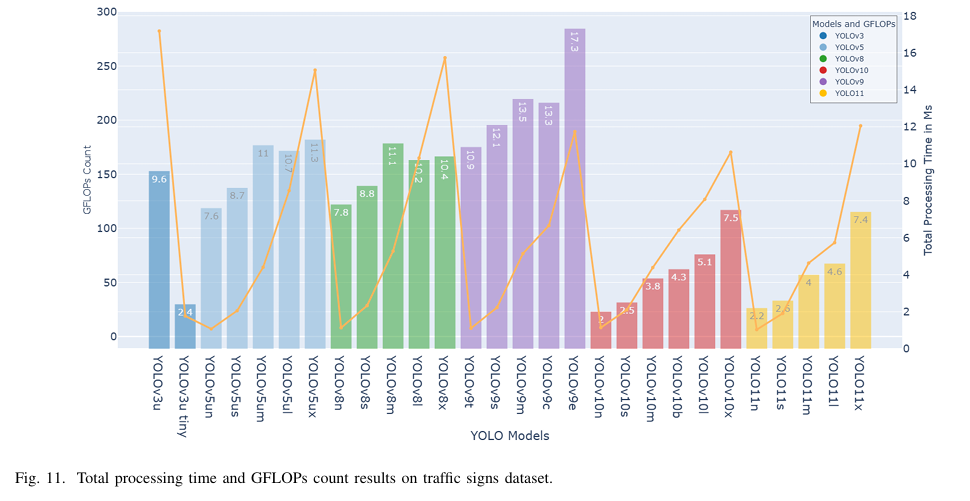
c) 计算效率:在计算效率方面,YOLOv10n是最有效的,每张图片的处理时间为2ms,GFLOPs计数为8.3,如图10和11所示。YOLO11n紧随其后,处理时间为2.2ms,GFLOPs计数为6.4,而YOLOv3u-tiny的处理时间为2.4ms,GFLOPs计数为19,与其他快速模型相比,这使得它在计算上相对低效。然而,数据显示YOLOv9e、YOLOv9m、YOLOv9c和YOLOv9s是效率最低的,推理时间分别为16.1ms、12.1ms、11.6ms和11.1ms,GFLOPs计数分别为189.4、76.7、102.6和26.8。这些发现描绘了一个明显的权衡,即在精度和计算效率之间。
d) 整体性能:在评估整体性能时,包括准确性、大小和模型效率,YOLO11m作为一个一致的表现最佳的模型脱颖而出。它实现了mAP50-95为0.795,推理时间为2.4ms,模型大小为38.8Mb,GFLOPs计数为67.9,如图8、10、11和表VI中详细说明的。紧随其后的是YOLO111(mAP50-95为0.794,推理时间为4.6ms,大小为49Mb,GFLOPs计数为86.8)和YOLOv10m(mAP50-95为0.781,推理时间为2.4ms,大小为32.1Mb,63.8 GFLOPs计数)。这些结果突显了这些模型在检测各种大小的交通标志方面的稳健性,同时保持了较短的推理时间和较小的模型大小。值得注意的是,YOLO11和YOLOv10家族在准确性和计算效率方面显著优于其他YOLO家族,因为它们的模型在这些数据集上一致超越了其他家族的对应物。
非洲野生动物数据集
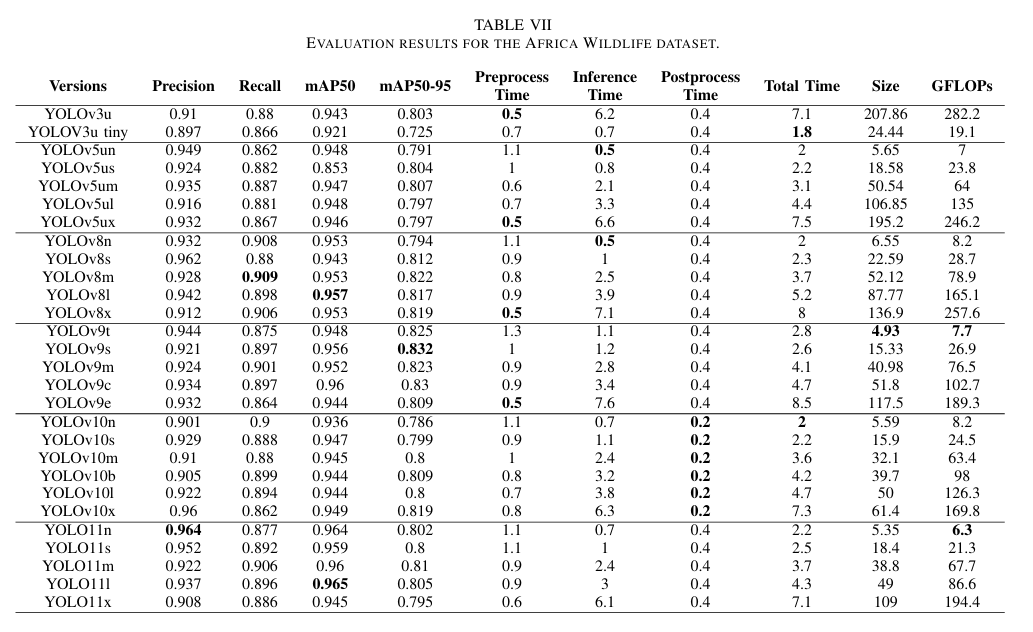
表 VII 展示了 YOLO 模型在非洲野生动物数据集上的性能。该数据集包含大型物体尺寸,重点关注 YOLO 模型预测大型物体的能力以及由于数据集大小而导致过拟合的风险。模型在各个方面的准确性都表现出色,最高性能的模型 mAP50-95 范围从 0.832 到 0.725。这个相对较短的范围反映了模型在检测和分类大型野生动物物体时保持高准确性的有效性。
a) 准确性:如图 12 所示,YOLOv9s 展现了出色的性能,具有高达 0.832 的 mAP50-95 和 0.956 的 mAP50,展示了其在各种 IoU 阈值下的稳健准确性。YOLOv9c 和 YOLOv9t 紧随其后,mAP50 分数分别为 0.96 和 0.948,召回率分别为 0.896。值得注意的是,YOLOv8n 实现了 mAP50-95 得分分别为 0.83 和 0.825。这些结果突出了 YOLOv9 系列从少量图像样本中有效学习模式的能力,使其特别适合于较小型的数据集。相比之下,YOLOv5un、YOLOv10n 和 YOLOv3u-tiny 显示出较低的 mAP50-95 得分,分别为 0.791、0.786 和 0.725,表明它们在准确性方面的局限性。较大的模型如 YOLO11x、YOLOv5ux、YOLOv5ul 和 YOLOv10l 的表现不佳,可以归因于过拟合,特别是考虑到数据集规模较小。
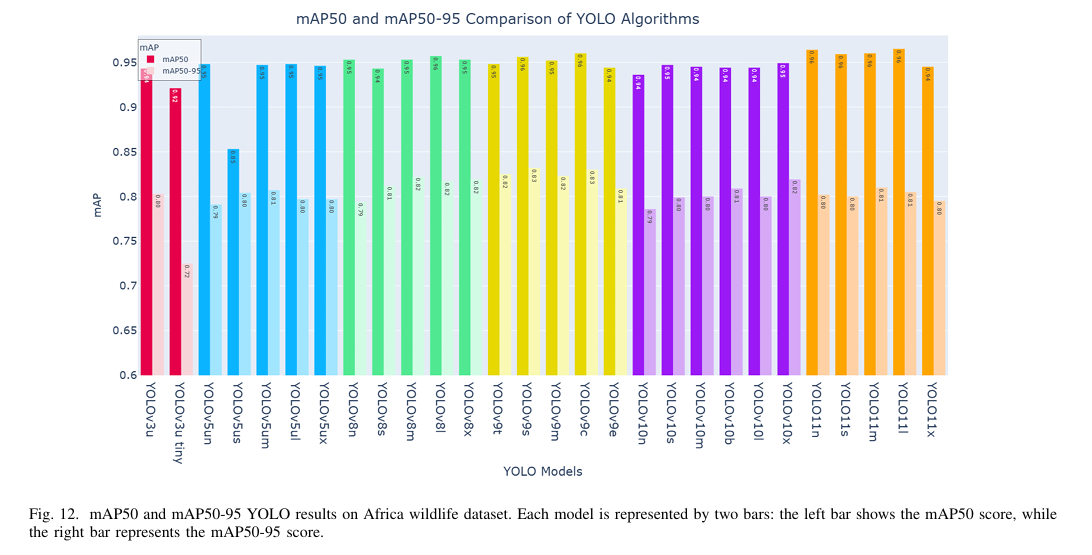
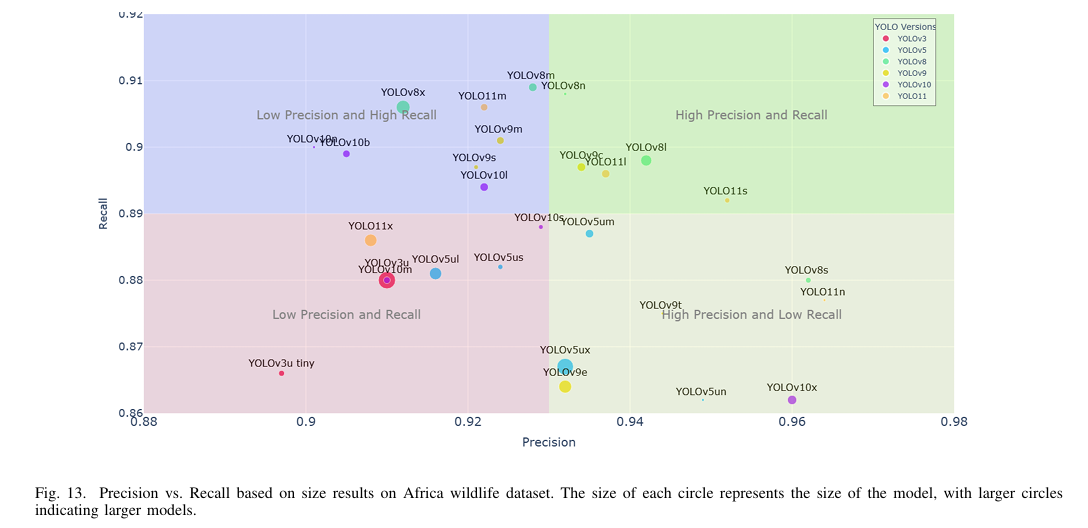
b) 精度和召回率:图 13 表明 YOLO8l 和 YOLO111 实现了最高的精度和召回率,精度值分别为 0.942 和 0.937,召回率分别为 0.898 和 0.896。值得注意的是,YOLOv8n 实现了 0.932 的精度和 0.908 的召回率。总体而言,YOLOv8l 和 YOLO111 在精度和召回率方面表现最佳,YOLOv8n 的表现也相当出色。然而,YOLOv11 模型倾向于产生误报,这反映在其较低的精度和较高的召回率上。与此同时,YOLOv10 在精度和召回率方面的表现均不佳,尽管它是 YOLO 系列中最新的模型之一。
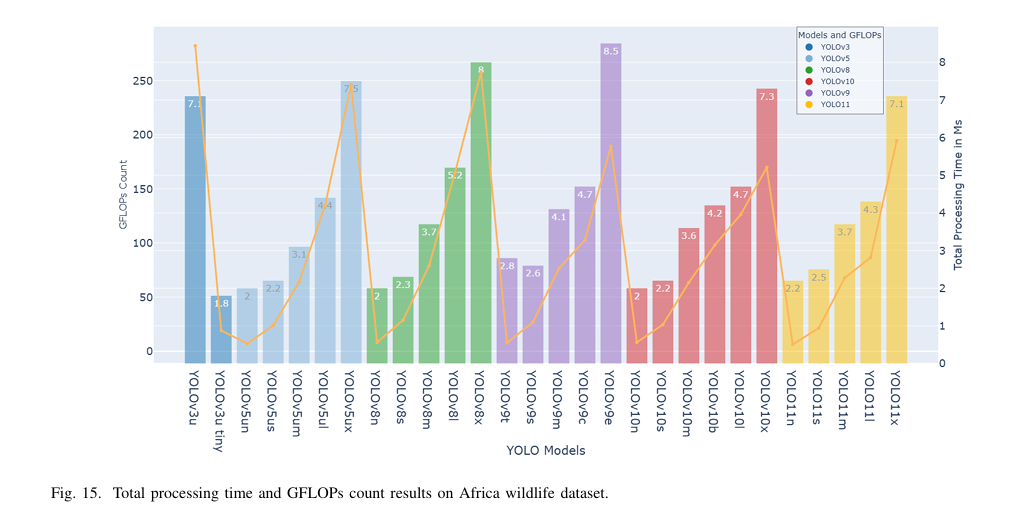
c) 计算效率:如图 14 和 15 所示,YOLOv10n、YOLOv8n 和 YOLOv3u-tiny 是最快的模型,处理时间分别为 2ms 和 1.8ms,GFLOPs 计数分别为 8.2 和 19.1。前两个模型具有相同的处理速度和 GFLOPs 计数,如表 VII 中所示。相比之下,YOLOv9e 展现了最慢的处理时间,为 11.2ms,GFLOPs 计数为 189.3,其次是 YOLOv5ux,处理时间为 7.5ms,GFLOPs 计数为 246.2 GFLOPs 计数。这些结果表明,较大的模型通常需要更多的处理时间和硬件资源,强调了模型大小和处理效率之间的权衡。
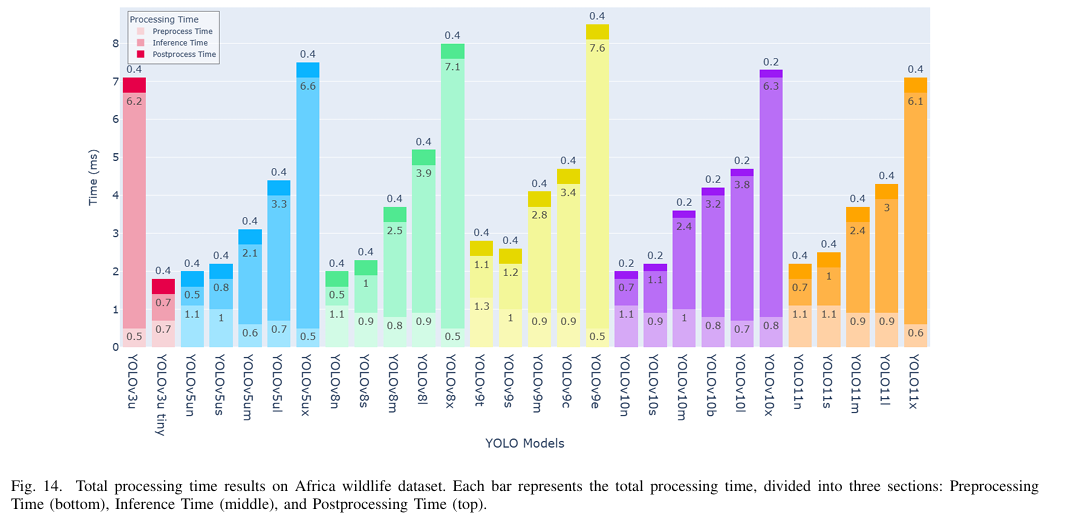
d) 整体性能:表 VII 和图 13、14 和 15 中的结果表明,YOLOv9t 和 YOLOv9s 在各个指标上持续表现出色,提供高准确性,同时保持较小的模型大小、低 GFLOPs 和短的处理时间,展示了 YOLOv9 较小型模型的稳健性及其在小数据集上的有效性。相比之下,YOLO5ux 和 YOLO11x 尽管具有较大的尺寸和较长的推理时间,但准确性表现不佳,可能是由于过拟合所致。大多数大型模型在这个数据集上的表现都不尽如人意,YOLOv10x 是一个例外,得益于现代架构防止过拟合,表现优异。
船只和船舶数据集:
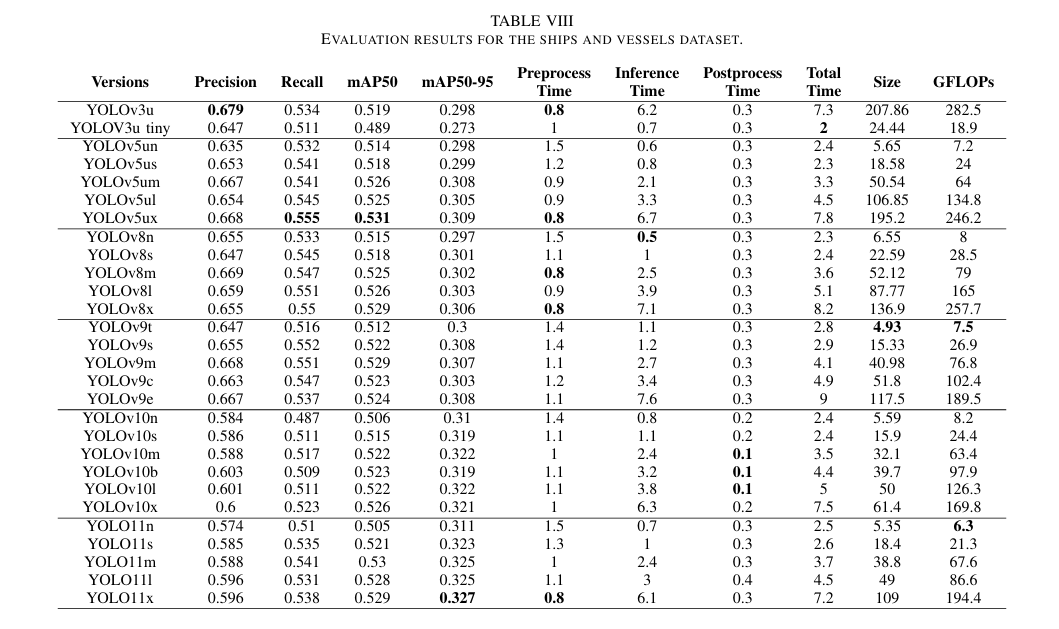
表 VIII 展示了 YOLO 模型在船只和船舶数据集上的性能,这是一个包含微小物体且旋转变化多样的大型数据集。总体而言,模型在检测船只和船舶方面表现出中等效果,mAP50-95 的范围从 0.273 到 0.327。这一表现表明 YOLO 算法在准确检测较小物体方面可能面临挑战,数据集中物体尺寸和旋转的多样性为测试模型能力提供了全面的测试。
a) 准确性:图 16 中 mAP50-95 和 mAP50 之间的差异凸显了 YOLO 模型在检测小物体时面临的挑战,尤其是在更高的 IoU 阈值下。此外,YOLO 模型在检测不同旋转的物体时也遇到困难。在各个模型中,YOLO11x 实现了最高的准确性,mAP50 为 0.529,mAP50-95 为 0.327,紧随其后的是 YOLO111、YOLO11m 和 YOLO11s,它们记录的 mAP50 值分别为 0.529、0.528 和 0.53,mAP50-95 值分别为 0.327、0.325 和 0.325。这些结果突出了 YOLO11 系列在检测小型和微小物体方面的稳健性。相比之下,YOLOv3u-tiny、YOLOv8n、YOLOv3u 和 YOLOv5n 展示了最低的准确性,mAP50 分数分别为 0.489、0.515、0.519 和 0.514,mAP50-95 分数分别为 0.273、0.297、0.298 和 0.298。这表明 YOLOv3u 的过时架构以及由于数据集规模较大而导致的小型模型的潜在欠拟合。
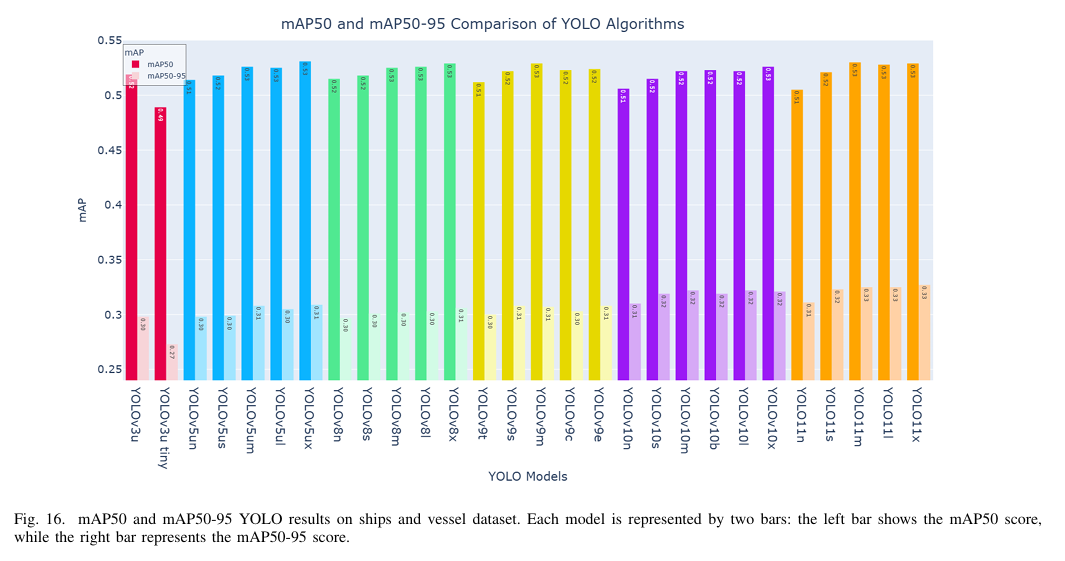
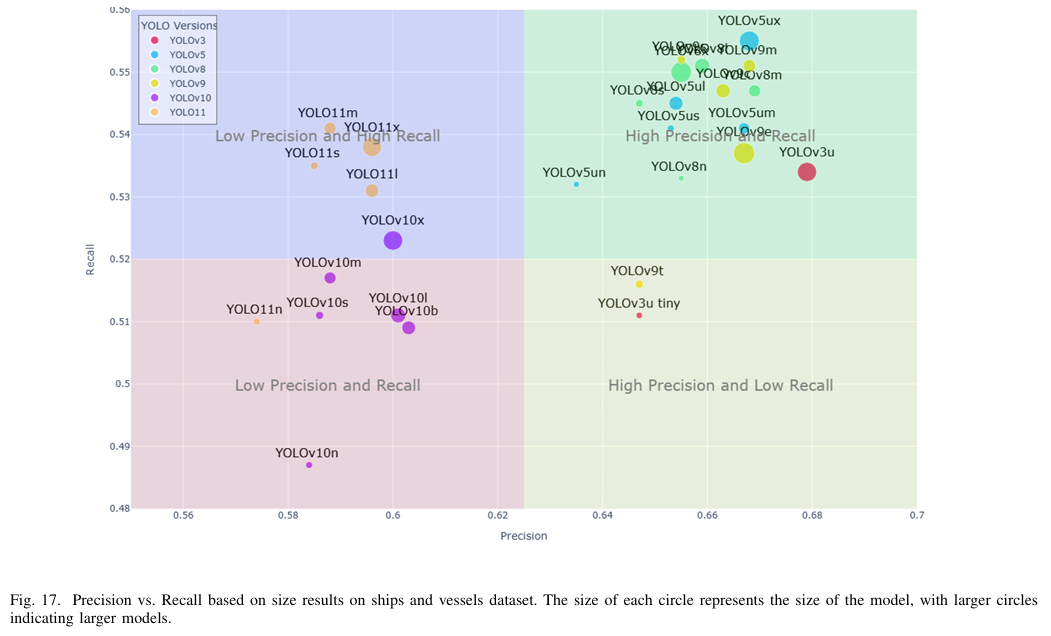
b) 精度和召回率:图 17 表明 YOLOv5ux 的表现优于其他模型,实现了 0.668 的精度和 0.555 的召回率。它紧随其后的是 YOLOv9m(精度为 0.668,召回率为 0.551)和 YOLOv8m(精度为 0.669,召回率为 0.525),两者在尺寸上显著较小(YOLOv9m 为 40.98 Mb,YOLOv8m 为 52.12 Mb)。相比之下,YOLO11n 和 YOLOv10s 表现较差,精度分别为 0.574 和 0.586,召回率分别为 0.51 和 0.511,这可能是由于欠拟合问题。总体而言,YOLO11 模型倾向于产生误报,这反映在其较低的精度和较高的召回率上。与此同时,YOLOv10 在精度和召回率方面的表现均不佳,尽管它是 YOLO 系列中最新的模型之一。
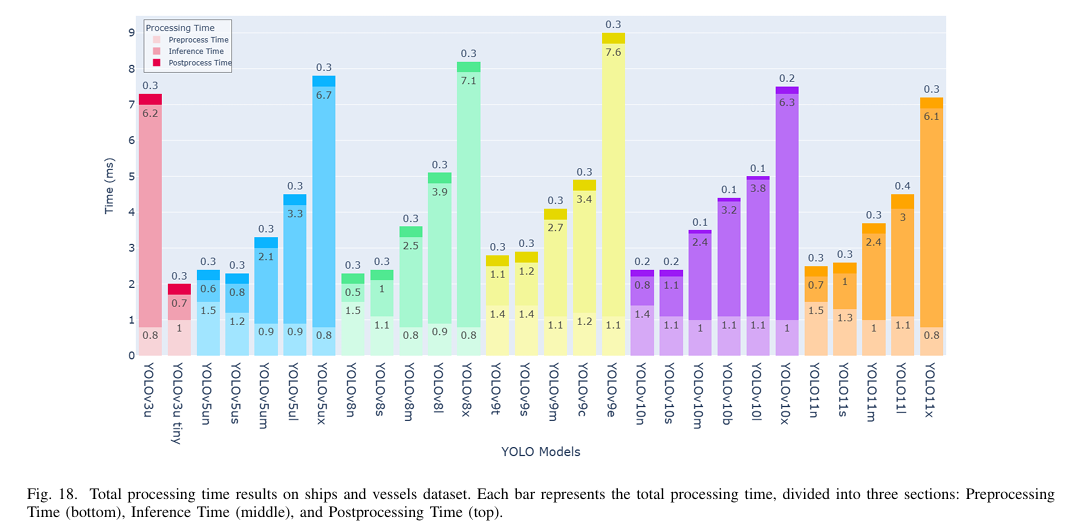
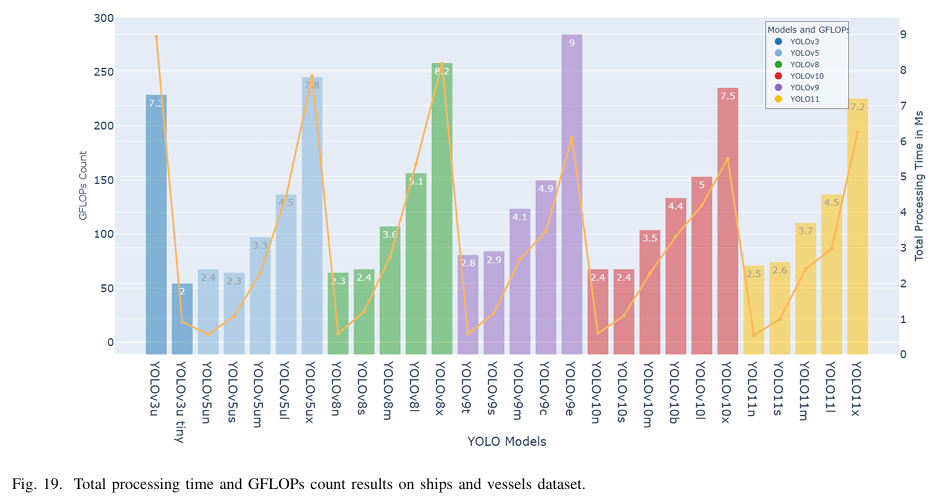
c) 计算效率:如图 18 和 19 所示,YOLOv3u-tiny 实现了最快的处理时间,为 2 毫秒,紧随其后的是 YOLOv8n 和 YOLOv5un,两者均记录了 2.3 毫秒。YOLOv10 和 YOLO11 模型也在速度上表现出色,YOLOv10n 和 YOLO11n 分别实现了 2.4 毫秒和 2.5 毫秒的快速推理时间,以及 8.2 和 6.3 的 GFLOPs 计数。相比之下,YOLOv9e 展现了最慢的速度,推理时间为 7.6 毫秒,GFLOPs 计数为 189.3,突显了 YOLOv9 系列在准确性和效率之间的权衡。
d) 整体性能:表 VIII 和图 16、17 和 18 中的结果表明,YOLO11s 和 YOLOv10s 在准确性方面表现优异,同时保持了紧凑的尺寸、低 GFLOPs 和快速的处理时间。相比之下,YOLOv3u、YOLOv8x 和 YOLOv8l 未能达到预期,尽管它们的尺寸较大且处理时间较长。这些发现突出了 YOLO11 系列的稳健性和可靠性,特别是在提高 YOLO 系列检测小型和微小物体的性能方面,同时确保高效处理。此外,结果还揭示了 YOLOv9 模型在面对大型数据集和小物体时的表现不佳,尽管它们具有现代架构。
讨论
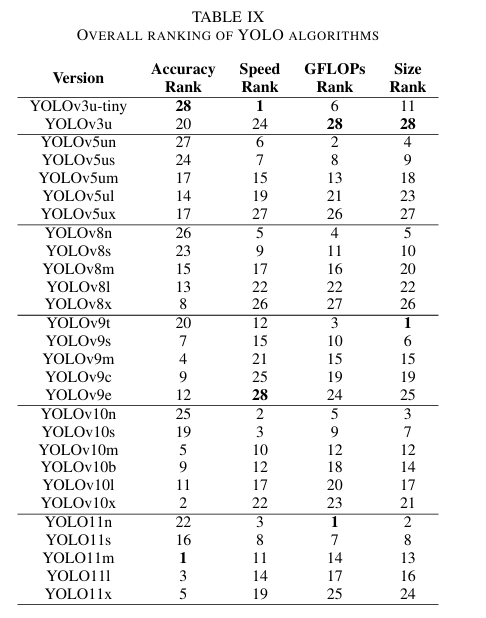
基于三个数据集上模型的性能,我们按准确性、速度、GFLOps 计数和大小对它们进行了排名,如表 IX 所示,以便进行全面评估。对于准确性,由于 mAP50-95 指标能够评估模型在一系列 IoU 阈值下的表现,因此我们采用了该指标。对于速度,模型根据总处理时间进行排序,总处理时间包括预处理、推理和后处理持续时间。排名范围从第 1 名(表示最高性能)到第 28 名(表示最低性能),表中的相应排名已加粗显示。
表 IX 的分析得出了几个关键观察结果:
- 准确性:YOLO11m 一致地成为顶级表现者,经常位居前列,紧随其后的是 YOLOv10x、YOLO111、YOLOv9m 和 YOLO11x。这突显了 YOLO11 系列在各种 IoU 阈值和物体大小下的稳健性能,这可以归因于它们使用 C2PSA 来保留上下文信息,从而提高了收敛性和整体性能。此外,大核卷积和部分自注意力模块的实施有助于提高算法的性能。
相比之下,YOLOv3u-tiny 展现了最低的准确性,特别是在非洲野生动物和船只及船舶数据集上,YOLOv5un 和 YOLOv8n 的表现稍好但仍不理想。这表明 YOLO11 模型目前是要求高准确性的应用中最可靠的。
紧随 YOLO11 系列之后,YOLOv9 模型在检测各种大小和不同 IoU 阈值的物体方面表现出色。然而,它们可能在检测小物体时遇到困难,这在船只和船舶数据集上可见。相比之下,YOLOv10 系列尽管推出较晚,但在交通标志和非洲动物数据集上的准确性相对较低,导致平均准确性下降了 2.075%,这可以归因于它们采用一对一头部方法而不是非极大值抑制(NMS)来定义边界框。这种策略在捕捉物体时可能会遇到困难,特别是在处理重叠物品时,因为它依赖于每个物体的单个预测。这一限制有助于解释第二个数据集中观察到的相对较差的结果。
YOLOv3u 的过时架构也导致了其性能不佳,平均准确性比 YOLO11 模型低 6.5%。这种下降可以追溯到其对 2018 年首次引入的较旧 Darknet-53 框架的依赖,该框架可能无法充分应对当代检测挑战。
- 计算效率:YOLOv10n 在速度和 GFLOPs 计数方面始终表现优异,在所有三个数据集上均名列前茅,在速度方面排名第 1,在 GFLOPs 计数方面排名第 5。YOLOv3u-tiny、YOLOv10s 和 YOLO11n 也展示了显著的计算效率。
YOLOv9e 展现了最慢的推理时间和非常高的 GFLOPs 计数,突显了准确性与效率之间的权衡。YOLO11 的速度提升可归因于它们使用的 C3k2 块,使其适用于需要快速处理的场景,超过了 YOLOv10 和 YOLOv9 模型,分别在速度上平均快了 %1.41 和 %31。
虽然 YOLOv9 模型在准确性方面表现出色,但它们的推理时间却是最慢的,使它们不太适合对时间敏感的应用。相比之下,YOLOv10 模型虽然略慢于 YOLO11 变体,但仍提供了效率与速度之间的值得称赞的平衡。它们的表现非常适合时间敏感的场景,提供快速处理而不显著牺牲准确性,使它们成为实时应用的可行选择。
- 模型大小:YOLOv9t 是最小的模型,在所有三个数据集上均排名第一,其次是 YOLO11n 和 YOLOv10n。这种模型大小的效率突显了较新 YOLO 版本,特别是 YOLOv10,在高效参数利用方面的进步,实施了空间-通道解耦下采样。
YOLOv3u 是最大的模型,突显了与其更现代的对应物相比,它的效率低下。
- 整体性能:考虑到准确性、速度、大小和 GFLOPs,YOLO11m、YOLOv11n、YOLO11s 和 YOLOv10s 成为最一致的表现者。它们实现了高准确性、低处理时间和功率以及高效的磁盘使用,使其适用于广泛的应用,其中速度和准确性都至关重要。
相反,YOLOv9e、YOLOv5ux 和 YOLOv3u 在所有指标上的表现都较差,计算效率低下且相对于其大小表现不佳。YOLO11 模型显示出最佳的整体性能,可能是由于最近的增强功能,如 C3k2 块和 C2PSA 模块。紧随其后的是 YOLOv10 模型,尽管在准确性方面略有逊色,但由于其一对一头部用于预测的实施,在效率方面表现出色。虽然 YOLOv9 在计算效率方面表现不佳,但它在准确性方面仍然具有竞争力,这要归功于其 PGI 集成。这使 YOLOv9 成为优先考虑精度而非速度的应用的可行选择。
此外,YOLOv8 和 YOLOv5u 展示了竞争性结果,超过了 YOLOv3u 的准确性,这可能是由于 YOLOv3u 的较旧架构。然而,它们的准确性仍然显著低于较新的模型,如 YOLOv9、YOLOv10 和 YOLO11。虽然 YOLOv8 和 YOLOv5u 的处理时间比 YOLOv9 快,但它们的整体表现仍然不如较新的模型。
- 物体大小和旋转检测:YOLO 算法在检测大中型物体方面效果很好,如非洲野生动物和交通标志数据集所证明的那样,准确性很高。然而,它在检测小物体方面存在困难,可能是由于将图像划分为网格,使得识别小而分辨率低的物体变得具有挑战性。此外,YOLO 在处理不同旋转的物体时也面临挑战,因为无法包围旋转物体,导致整体结果不佳。
为了处理旋转物体,可以实现像 YOLO11 OBB[26] 和 YOLOv8 OBB[25](定向边界框)这样的模型。保持与标准 YOLOv8 和 YOLO11 相同的基础架构,YOLOv8 OBB 和 YOLO11 OBB 用预测旋转矩形四个角点的头部替换了标准边界框预测头部,允许更准确的定位和表示任意方向的物体。
YOLO11 对 YOLOv8 的崛起:尽管 YOLOv8[25] 因其在姿态估计、实例分割和定向物体检测(OBB)任务中的多功能性而成为算法的首选,但 YOLO11[26] 已经成为一个更高效和准确的替代品。通过处理相同任务的同时提供改进的上下文理解和更好的架构模块,YOLO11 设定了新的性能标准,在各种应用中的速度和准确性方面都超过了 YOLOv8。
数据集大小:数据集的大小显著影响 YOLO 模型的性能。例如,大型模型在小型非洲野生动物数据集上的表现不如在交通标志和船只及船舶数据集上的表现,因为它们更容易过拟合。相反,像 YOLOv9t 和 YOLOv9s 这样的小模型在非洲野生动物数据集上的表现显著更好,展示了小规模模型在处理有限数据集时的有效性。
训练数据集的影响:如表 VI、VII 和 VIII 所示,YOLO 模型的性能受到所使用的训练数据集的影响。不同的数据集产生不同的结果和顶尖表现者,表明数据集复杂性影响算法性能。这突显了在基准测试期间使用多样化数据集以获得每个模型优缺点全面结果的重要性。
这次讨论强调了在选择 YOLO 模型进行特定应用时,需要平衡考虑准确性、速度和模型大小。YOLO11 模型在各个指标上的一致表现使它们非常适合于需要准确性和速度的多功能场景。同时,YOLOv10 模型可以在保持更快处理时间和更小模型大小的同时,类似地执行。此外,YOLOv9 可以在准确性方面提供可比的结果,但牺牲了速度,使其适用于优先考虑精度而非快速处理的应用。
结论
这项基准研究全面评估了各种 YOLO 算法的性能。它是首个对 YOLO11 及其前辈进行全面比较的研究,评估了它们在三个多样化数据集上的表现:交通标志、非洲野生动物和船只及船舶。这些数据集经过精心挑选,包含了广泛的物体属性,包括不同的物体大小、宽高比和物体密度。我们通过检查精度、召回率、平均精度均值(mAP)、处理时间、GFLOPs 计数和模型大小等一系列指标,展示了每个 YOLO 版本和家族的优势和劣势。我们的研究解决了以下关键研究问题:
● 哪个 YOLO 算法在一系列综合指标上展示了卓越的性能?
● 不同的 YOLO 版本在具有不同物体特征(如大小、宽高比和密度)的数据集上的表现如何?
● 每个 YOLO 版本的具体优势和局限性是什么,这些见解如何指导选择最适合各种应用的算法?
特别是,YOLO11 系列作为最一致的表现在各个指标上脱颖而出,YOLO11m 在准确性、效率、模型大小之间取得了最佳平衡。虽然 YOLOv10 的准确性略低于 YOLO11,但它在速度和效率方面表现出色,使其成为需要效率和快速处理的应用的强有力选择。此外,YOLOv9 总体上也表现良好,特别是在较小的数据集上表现尤为突出。这些发现为工业界和学术界提供了宝贵的见解,指导选择最适合的 YOLO 算法,并为未来的发展和改进提供信息。虽然评估的算法展示了有希望的性能,但仍有一些改进的空间。未来的研究可以专注于优化 YOLOv10,以提高其准确性,同时保持其速度和效率优势。此外,架构设计的持续进步可能为更突破性的 YOLO 算法铺平道路。我们未来的工作包括深入研究这些算法中确定的差距,并提出改进措施,以展示它们对整体效率的潜在影响。
其它问题
- 在交通标志数据集上,YOLOv5ul和YOLOv10n的性能差异是什么?原因是什么?
在交通标志数据集上,YOLOv5ul的mAP50-95达到了0.799,而YOLOv10n的mAP50-95仅为0.64,相差显著。YOLOv5ul在精度和召回率上都表现更好,具体来说,YOLOv5ul的Precision为0.866,Recall为0.849,而YOLOv10n的Precision为0.722,Recall为0.602。这种差异的原因可能包括:
- 模型架构改进:YOLOv5ul采用了更先进的CSPDarknet53作为主干网络,并引入了Spatial Pyramid Pooling Fast(SPPF)模块,这些改进提高了模型的特征提取能力和多尺度适应性。
- 数据增强:YOLOv5ul使用了多种数据增强技术,如Mosaic、Copy-Paste、Random Affine等,这些技术有助于提高模型的泛化能力和鲁棒性。
- 优化策略:YOLOv5ul在训练过程中使用了更有效的优化策略,如AdamW优化器和学习率调度,这些策略有助于模型更快地收敛和提高性能。
- 在船舶与船只数据集上,YOLOv11x为什么表现最好?与其他模型相比有哪些优势?
在船舶与船只数据集上,YOLOv11x的mAP50-95达到了0.327,表现最好。与其他模型相比,YOLOv11x有以下优势:
- 小对象检测:YOLOv11x特别适用于检测小对象,能够在复杂的图像环境中准确识别和定位小尺寸的船只。
- 架构改进:YOLOv11x引入了C3k2块和C2PSA(Cross-Stage Partial with Self-Attention)模块,这些改进提高了模型的空间注意力和特征提取能力,特别是在处理重叠和小的对象时表现优异。
- 计算效率:尽管YOLOv11x在精度上有所提升,但其推理时间仍然保持在2.4ms左右,保持了较高的计算效率,适合实时应用。
在非洲野生动物数据集上,YOLOv9s的表现优于其他模型的原因是什么?
在非洲野生动物数据集上,YOLOv9s的mAP50-95达到了0.832,表现优于其他模型。YOLOv9s之所以表现优异,主要原因包括:
- 小型数据集适应性:YOLOv9s在小型数据集上表现出色,能够有效学习对象的模式。其小型模型(如YOLOv9t)在非洲野生动物数据集上表现尤为突出,mAP50-95为0.832,mAP50为0.956。
- 特征提取能力:YOLOv9s采用了CSPNet(Cross-Stage Partial Network),这种结构通过分割特征图来提高特征提取效率,减少了计算复杂度。
- 正则化技术:YOLOv9s使用了GelAN(Gradient Enhanced Lightweight Architecture Network),这种技术通过优化网络内的计算路径,提高了参数利用率和计算效率。
