YOLO11 详解
Last updated on December 9, 2024 pm
2024 年是 YOLO 模型的一年。在 2023 年发布 Ultralytics YOLOv8 之后, YOLOv9 和 YOLOv10也在2024年发布了。但等等,这还不是结束!Ultralytics YOLO11 终于来了,在激动人心的 YOLO Vision 2024 (YV24) 活动中亮相。

YOLO11 系列是 YOLO 系列中最先进的 (SOTA)、最轻、最高效的型号,性能优于其前代产品。它由 Ultralytics 创建,该组织发布了 YOLOv8,这是迄今为止最稳定和使用最广泛的 YOLO 变体。现在,YOLO11 将继续 YOLO 系列的传统。在本文中,我们将探讨:
- 什么是 YOLO11?
- YOLO11 能做什么?
- YOLO11 比其他 YOLO 变体更高效吗?
- YOLO11 架构有哪些改进?
- YOLO11 的代码pipeline是如何工作的?
- YOLO11 的基准测试
- YOLO11 快速回顾
什么是YOLO11

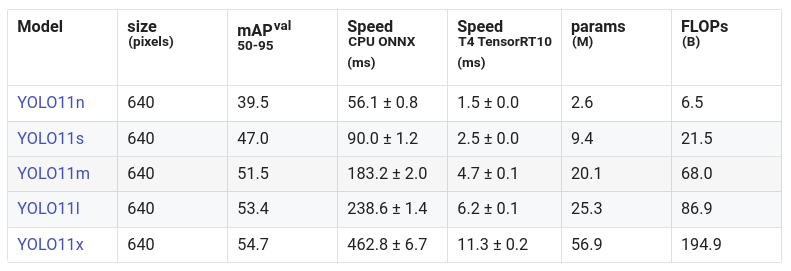
YOLO11 是 Ultralytics 的 YOLO 系列的最新版本。YOLO11 配备了超轻量级型号,比以前的 YOLO 更快、更高效。YOLO11 能够执行更广泛的计算机视觉任务。Ultralytics 根据大小发布了 5 个 YOLO11 模型,并在所有任务中发布了 25 个模型:
- YOLO11n – Nano 适用于小型和轻量级任务。
- YOLO11s – Nano 的小升级,具有一些额外的准确性。
- YOLO11m – 通用型。
- YOLO11l – 大,精度更高,计算量更高。
- YOLO11x – 超大尺寸,可实现最大精度和性能。
YOLO11 构建在 Ultralytics YOLOv8 代码库之上,并进行了一些架构修改。它还集成了以前 YOLO(如 YOLOv9 和 YOLOv10)的新功能(改进这些功能)以提高性能。我们将在博客文章的后面部分探讨架构和代码库中的新变化。
YOLO11的应用
YOLO 以其对象检测模型而闻名。但是,YOLO11 可以执行多个计算机视觉任务,例如 YOLOv8。它包括:
- 对象检测
- 实例分段
- 图像分类
- 姿势估计
- 定向目标检测 (OBB)
让我们来探索所有这些。
对象检测

YOLO11 通过将输入图像传递到 CNN 以提取特征来执行对象检测。然后,网络预测这些网格中对象的边界框和类概率。为了处理多尺度检测,使用图层来确保检测到各种大小的物体。然后使用非极大值抑制 (NMS) 来优化这些预测,以过滤掉重复或低置信度的框,从而获得更准确的对象检测。YOLO11 在 MS-COCO 数据集上进行对象检测训练,其中包括 80 个预训练类。
实例分割

除了检测对象之外,YOLO11 还通过添加掩码预测分支扩展到实例分割。这些模型在 MS-COCO 数据集上进行训练,其中包括 80 个预训练类。此分支为每个检测到的对象生成像素级分割掩码,使模型能够区分重叠的对象并提供其形状的精确轮廓。head 中的蒙版分支处理特征映射并输出对象蒙版,从而在识别和区分图像中的对象时实现像素级精度。
姿势估计

YOLO11 通过检测和预测物体上的关键点(例如人体的关节)来执行姿态估计。关键点连接起来形成骨架结构,该结构表示姿势。这些模型在 COCO 上进行训练,其中包括一个预先训练的类“person”。
在头部添加姿态估计层,并训练网络预测关键点的坐标。后处理步骤将点连接起来以形成骨架结构,从而实现实时姿势识别。
图像分类

对于图像分类,YOLO11 使用其深度神经网络从输入图像中提取高级特征,并将其分配给多个预定义类别之一。这些模型在 ImageNet 上进行训练,其中包括 1000 个预训练类。该网络通过多层卷积和池化处理图像,在增强基本特征的同时减少空间维度。网络顶部的分类头输出预测的类,使其适用于需要识别图像整体类别的任务。
定向目标检测 (OBB)

YOLO11 通过整合 OBB 扩展了常规对象检测,使模型能够检测和分类旋转或不规则方向的物体。这对于航空影像分析等应用程序特别有用。这些模型在 DOTAv1 上进行训练,其中包括 15 个预训练类。
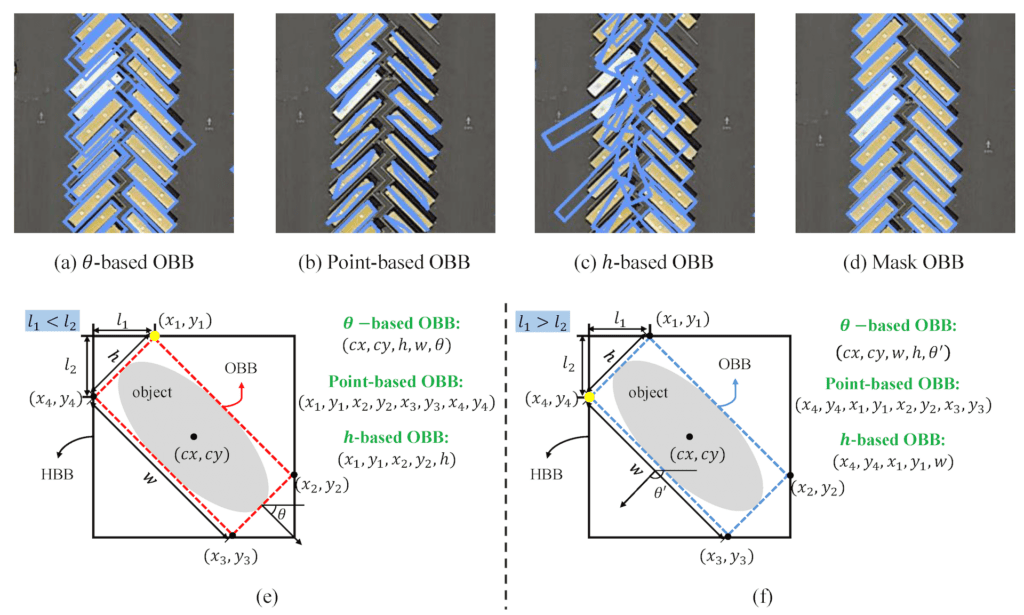
OBB 模型不仅输出边界框坐标,还输出旋转角度 (θ) 或四个角点。这些坐标用于创建与对象方向对齐的边界框,从而提高旋转对象的检测准确性。
YOLO11 架构和 YOLO11 中的新增功能
YOLO11 架构是对 YOLOv8 架构的升级,具有一些新的集成和参数调整。在我们继续主要部分之前,您可以查看我们关于 YOLOv8 的详细文章以大致了解架构。现在,如果你看一下 YOLO11 的配置文件:
1 | |
架构级别的变化:
1. 骨干
主干是模型的一部分,用于从多个比例的输入图像中提取特征。它通常涉及堆叠卷积层和块以创建不同分辨率的特征图。
卷积层:YOLO11 具有类似的结构,带有初始卷积层来对图像进行下采样:
1 | |
C3k2 区块:YOLO11 引入了 C3k2 块,而不是 C2f,它在计算方面效率更高。此块是 CSP 瓶颈的自定义实现,它使用两个卷积,而不是一个大型卷积(如 YOLOv8 中所示)。
- CSP (Cross Stage Partial):CSP 网络拆分特征图并通过瓶颈层处理一部分,同时将另一部分与瓶颈的输出合并。这减少了计算负载并改善了特征表示。
1
- [-1, 2, C3k2, [256, False, 0.25]]- C3k2 块还使用较小的内核大小(由 k2 表示),使其更快,同时保持性能。
SPPF 和 C2PSA:YOLO11 保留了 SPPF 块,但在 SPPF 之后添加了一个新的 C2PSA 块:
1 | |
- C2PSA (Cross Stage Partial with Spatial Attention) 模块增强了特征图中的空间注意力,从而提高了模型对图像重要部分的关注。这使模型能够通过在空间上池化特征来更有效地关注特定的感兴趣区域。
2. neck
neck 负责聚合来自不同分辨率的特征,并将它们传递给头部进行预测。它通常涉及来自不同级别的特征图的上采样和连接。
C3k2 区块:YOLO11 用 C3k2 块替换了颈部的 C2f 块。如前所述,C3k2 是一个更快、更高效的区块。例如,在上采样和串联后,YOLO11 中的 neck 如下所示:
1 | |
- 此更改提高了要素聚合过程的速度和性能。
- 注意力机制:YOLO11 通过 C2PSA 更侧重于空间注意力,这有助于模型专注于图像中的关键区域,以便更好地检测。这在 YOLOv8 中是缺失的,这使得 YOLO11 在检测较小或被遮挡的对象时可能更准确。
3. head
head 是模型中负责生成最终预测的部分。在对象检测中,这通常意味着生成边界框并对这些框内的对象进行分类。
C3k2 区块:与颈部类似,YOLO11 取代了头部的 C2f 块。
1 | |
检测层:最终的 Detect 层与 YOLOv8 中的层相同:
1 | |
使用 C3k2 块使模型在推理方面更快,在参数方面更高效。
那么,让我们看看新块(层)在代码中的样子:
那么,让我们看看新块(层)在代码中的样子:
- C3k2 区块(从 blocks.py 开始):
- C3k2 是 CSP 瓶颈的更快、更高效的变体。它使用两个卷积而不是一个大型卷积,从而加快了特征提取速度。
1 | |
- C3k 块(从 blocks.py 开始):
- C3k 是一个更灵活的瓶颈模块,允许自定义内核大小。这对于提取图像中更详细的特征非常有用。
1 | |
- C2PSA 块(从 blocks.py 年起):
- C2PSA (Cross Stage Partial with Spatial Attention) 增强了模型的空间注意力能力。此模块增加了对特征图的关注,帮助模型专注于图像的重要区域。
1 | |
YOLO11 pipeline
在 ultralytics GitHub 仓库中,我们将主要关注:
- nn/modules/ 中的模块
- block.py
- conv.py
- head.py
- transformer.py
- utils.py
- nn/tasks.py 文件
1. 代码库概述
代码库被构建为多个模块,这些模块定义了 YOLO11 模型中使用的各种神经网络组件。这些组件在 nn/modules/ 目录中被组织到不同的文件中:
- block.py:定义模型中使用的各种构建块(模块),例如瓶颈、CSP 模块和注意力机制。
- conv.py:包含卷积模块,包括标准卷积、深度卷积和其他变体。
- head.py:实现负责生成最终预测(例如,边界框、类概率)的模型头。
- transformer.py:包括基于 transformer 的模块,用于注意力机制和高级特征提取。
- utils.py:提供跨模块使用的实用程序函数和帮助程序类。
nn/tasks.py 文件定义了不同的特定于任务的模型(例如,检测、分割、分类),这些模型将这些模块组合成完整的架构。
2. nn/modules/ 中的模块
如前所述,YOLO11 构建在 YOLOv8 代码库之上。因此,我们将主要关注更新的脚本:block.py、conv.py 和 head.py 在这里。
block.py
此文件定义 YOLO11 模型中使用的各种构建块。这些块是构成神经网络层的基本组件。
关键组件:
- 瓶颈模块:
- Bottleneck:具有可选快捷方式连接的标准瓶颈模块。
- Res:使用一系列卷积和身份快捷方式的残差块。
1 | |
- Bottleneck 类实现了一个 bottleneck 模块,该模块减少了通道的数量(降维),然后再次扩展它们。
- 组件:
- self.cv1:一个 1×1 卷积,用于减少通道数。
- self.cv2:一个 3×3 卷积,用于将通道数增加回原始通道数。
- self.add:一个布尔值,指示是否添加快捷方式连接。
- Forward Pass:输入 x 通过 cv1 和 cv2 传递。如果 self.add 为 True,则原始输入 x 将添加到输出(残差连接)。
- CSP (Cross Stage Partial) 模块:
- BottleneckCSP:瓶颈模块的 CSP 版本。
- CSPBlock:具有多个瓶颈层的更复杂的 CSP 模块。
1 | |
- CSPBottleneck 模块将特征图分为两部分。一部分通过一系列瓶颈层,另一部分直接连接到输出,从而降低了计算成本并增强了梯度流。
- 组件:
- self.cv1:减少通道数。
- self.cv2:瓶颈层序列。
- self.cv3:合并功能并调整通道数。
- self.add:确定是否添加快捷方式连接。
- 其他模块:
- SPPF:Spatial Pyramid Pooling Fast 模块,可在多个比例下执行池化。
- Concat:沿指定维度连接多个 Tensor。
1 | |
- SPPF 模块在不同比例下执行最大池化,并将结果连接起来以捕获多个空间比例的要素。
- 组件:
- self.cv1:减少通道数。
- self.cv2:调整拼接后的 Channel 数。
- self.m:最大池化层数。
- Forward Pass:输入 x 通过 cv1,然后通过三个连续的最大池化层(y1、y2、y3)。结果被连接并通过 cv2 传递。
了解概念:
- 瓶颈层:用于通过在昂贵的操作之前减少通道数并在之后增加通道数来降低计算复杂性。
- 残差连接:通过缓解梯度消失问题来帮助训练更深的网络。
- CSP 架构:将特征图分为两部分;一部分发生转换,而另一部分保持不变,从而提高学习能力并减少计算。
conv.py
此文件包含各种卷积模块,包括标准卷积和专用卷积。
关键组件:
标准卷积模块 (Conv):
1 | |
- 实现具有批量规范化和激活的标准卷积层。
- 组件:
- self.conv:卷积层。
- self.bn:批量规范化。
- self.act:激活函数(默认为 nn.SiLU())的
- Forward Pass:应用卷积,然后进行批量规范化和激活。
深度卷积 (DWConv):
1 | |
- 执行深度卷积,其中每个输入通道单独卷积。
- 组件:
- 继承自 Conv。
- 将 groups 参数设置为 c1 和 c2 的最大公约数,从而有效地对每个通道的卷积进行分组。
- 其他卷积模块:
- Conv2:RepConv 的简化版本,用于模型压缩和加速。
- GhostConv:实现 GhostNet 的 ghost 模块,减少特性图中的冗余。
- RepConv:可重新参数化的卷积层,可以从训练模式转换为推理模式。
了解概念:
- 自动填充 (autopad):自动计算保持输出尺寸一致所需的填充。
- 深度卷积和点卷积:用于 MobileNet 架构,以减少计算,同时保持准确性。
- 重新参数化:RepConv 等技术通过合并层来实现高效的训练和更快的推理。
head.py
此文件实现了负责生成模型最终预测的 head 模块。
关键组件:
检测头 (Detect):
1 | |
- Detect 类定义输出边界框坐标和类概率的检测头。
- 组件:
- self.cv2:用于边界框回归的卷积层。
- self.cv3:用于分类的卷积层。
- self.dfl:用于边界框细化的 Distribution Focal Loss 模块。
- Forward Pass:处理输入特征映射并输出边界框和类的预测。
分割 (Segment):
1 | |
- 扩展 Detect 类以包含分段功能。
- 组件:
- self.proto:生成掩码原型。
- self.cv4:掩码系数的卷积层。
- Forward Pass:输出边界框、类概率和掩码系数。
姿势估计头部 (Pose):
1 | |
- 扩展了 Detect 类,用于人体姿势估计任务。
- 组件:
- self.kpt_shape:关键点的形状(关键点的数量、每个关键点的维度)。
- self.cv4:用于关键点回归的卷积层。
- Forward Pass:输出边界框、类概率和关键点坐标。
了解概念:
- 模块化:通过扩展 Detect 类,我们可以为不同的任务创建专门的 head,同时重用通用功能。
- 无锚点检测:现代对象检测器通常使用无锚点方法,直接预测边界框。
- 关键点估计:在姿势估计中,模型预测表示关节或地标的关键点。
3. nn/tasks.py 文件
1 | |
此 tasks.py 脚本是代码管道的核心部分;它仍然使用 YOLOv8 方法和逻辑;我们只需要将 YOLO11 模型解析到其中。此脚本专为各种计算机视觉任务而设计,例如对象检测、分割、分类、姿势估计、OBB 等。它定义了用于训练、推理和模型管理的基础模型、特定于任务的模型和效用函数。
关键组件:
- Imports:该脚本从 Ultralytics 导入 PyTorch (torch)、神经网络层 (torch.nn) 和实用函数等基本模块。一些关键导入包括:
- 对 C3k2、C2PSA、C3、SPPF、****Concat 等架构模块进行建模。
- 损失函数,如 v8DetectionLoss、v8SegmentationLoss、v8ClassificationLoss、v8OBBLoss。
- 各种实用程序函数,如 model_info、fuse_conv_and_bn、scale_img time_sync,以帮助进行模型处理、分析和评估。
模型基类:
- BaseModel 类:
- BaseModel 用作 Ultralytics YOLO 系列中所有模型的基类。
- 实现如下基本方法:
- forward():根据输入数据处理训练和推理。
- predict():处理前向传递以进行推理。
- fuse():融合 Conv2d 和 BatchNorm2d 层以提高效率。
- info():提供详细的模型信息。
- 此类旨在通过特定于任务的模型(例如检测、分割和分类)进行扩展。
- DetectionModel 类:
- 扩展 BaseModel,专门用于对象检测任务。
- 加载模型配置,初始化检测头(如 Detect 模块)并设置模型步幅。
- 它支持使用 YOLOv8 等架构的检测任务,并可以通过 _predict_augment() 执行增强推理。
特定于任务的模型:
- SegmentationModel 的 SegmentationModel 中:
- 专门用于分割任务(如 YOLOv8 分割)的 DetectionModel 的子类。
- 初始化特定于分割的损失函数 (v8SegmentationLoss)。
- PoseModel 的 PoseModel 中:
- 通过初始化具有关键点检测 (kpt_shape) 特定配置的模型来处理姿态估计任务。
- 使用 v8PoseLoss 进行特定于姿势的损失计算。
- 分类型号****:
- 专为使用 YOLOv8 分类架构的图像分类任务而设计。
- 初始化和管理特定于分类的损失 (v8ClassificationLoss)。
- 它还支持重塑用于分类任务的预训练 TorchVision 模型。
- OBB型号****:
- 用于定向边界框 (OBB) 检测任务。
- 实现特定的损失函数 (v8OBBLoss) 来处理旋转的边界框。
- 世界模型****:
- 此模型处理图像字幕和基于文本的识别等任务。
- 利用 CLIP 模型中的文本特征执行基于文本的视觉识别任务。
- 包括对文本嵌入 (txt_feats) 的特殊处理,用于字幕和世界相关任务。
集成模型:
- 集成****:
- 一个简单的 ensemble 类,它将多个模型合并为一个模型。
- 允许对不同模型的输出进行平均或串联,以提高整体性能。
- 对于组合多个模型的输出提供更好的预测的任务非常有用。
实用功能:
- 模型加载和管理:
- attempt_load_weights()、****attempt_load_one_weight():用于加载模型、管理集成模型以及处理加载预训练权重时的兼容性问题的函数。
- 这些功能可确保以适当的步幅、层和配置正确加载模型。
- 临时模块重定向:
- temporary_modules():一个上下文管理器,用于临时重定向模块路径,确保在模块位置更改时向后兼容。
- 有助于保持与旧型号版本的兼容性。
- Pickle安全处理:
- SafeUnpickler:一个自定义的解封器,可以安全地加载模型检查点,确保未知类被安全的占位符(SafeClass)替换,以避免在加载过程中发生崩溃。
模型解析:
- parse_model() 中:
- 此函数将 YAML 文件中的模型配置解析为 PyTorch 模型。
- 它处理主干和头架构,解释每个层类型(如 Conv、SPPF、Detect),并构建最终模型。
- 支持各种架构,包括 C3k2、C2PSA 等 YOLO11 组件。
- YAML 模型加载:
- yaml_model_load()):从 YAML 文件加载模型配置,检测模型比例(例如 n、s、m、l、x)并相应地调整参数。
- guess_model_scale()、****guess_model_task():用于根据 YAML 文件结构推断模型规模和任务的辅助函数。